After a nice weekend away I'm wondering where my machine at work has got to.
It was fine when I left it on Thursday, but sometime Friday afternoon it vanished without trace. Can't log in. Can't ping it. No nothing.
I can get into my other machine (that I use for OpenSolaris testing) just fine. That's connected into the same switch, powered off the same extension lead. So it's not a network or power problem.
Oh well, I guess I'll find out what hapened to it when I get in to the office tomorrow.
Sunday, February 26, 2006
Thursday, February 23, 2006
Affordable Sun Gear
Over on OpenSolaris.org, I jumped into a discussion regarding the availability - or more accurately lack of - a cheap sparc desktop machine.
At the present time, Sun sell a number of desktop sparc machines: SunBlade 150, SunBlade 1500, SunBlade 2500, and the new Ultra 45.
Frankly, why they're still selling the 150 is beyond me - it wasn't exactly quick when it was introduced in 2002 and it's a painful experience trying to use one with modern bloated software. It's horrifically expensive, and the available configurations aren't up to much. £2000 for a crippled antique? No thankyou...
The SunBlade 1500 isn't really that bad a machine. It's still over £2000, but it's not that much more than the 150 and is 2-3 times better. Still, £2000 just to get off the ground? Heavens...
I'll skip the 2500, as I think the Ultra 45 is similarly specified, but with a little more expansion and future-proofing. The starting price isn't that much more than a 1500 either, but rapdily rises.
All these boxes are out of my price range as an individual, and I couldn't really justify an employer buying them either.
The more powerful boxes are better value, but you have to pay for the privilege.
As far as I'm concerned, a reasonable entry-level box would be something like the SB1500, at about £1000 or so. Doesn't have to be fancy, but XVR-100 graphics and 512M memory minimum.
There's a similar story when it comes to sparc servers. Sun still sell the V100 and V120. OK, so there's a good market, and these machines have their uses. And they don't have much competition - there aren't many other machines of that low a spec out there.
At least with servers you definitely get into value-for-money territory as you move up the range. Certainly any of the T1 (Niagara) boxes are awesome. But there isn't much value in the sub £5000 space. Again, something like a V100 but with a modern US-IIIi processor at just over the £1000 mark would be handy.
The whole sparc low-end lineup looks incredibly stale. Even the Ultra 45 isn't much more than a SB2500 rehash (a good rehash, but still a rehash).
As might be expected, there's more in the Opteron world down at the low end. You can't really quarrel with the X2100 and Ultra 20.
But even here, Sun make it hard to get something decent. The problem (and this afflicts the whole of the range) is the lack of configuration choice. They seem to make the basic assumption that there's a cheap and nasty option that has the minimum of everything, then have another option in which most things are upgraded, and maybe another option in which everything is maxed out. That's not what I want. I don't want to have to pay for a fancy graphics card just to get a faster cpu, or the other way round. And sometimes I might actually want the base system with a 250G drive. Most PC vendors I look at allow you to select the various components of the system independently, so that I can put together a system that's balanced to meet my needs, but Sun won't let me do that.
At the present time, Sun sell a number of desktop sparc machines: SunBlade 150, SunBlade 1500, SunBlade 2500, and the new Ultra 45.
Frankly, why they're still selling the 150 is beyond me - it wasn't exactly quick when it was introduced in 2002 and it's a painful experience trying to use one with modern bloated software. It's horrifically expensive, and the available configurations aren't up to much. £2000 for a crippled antique? No thankyou...
The SunBlade 1500 isn't really that bad a machine. It's still over £2000, but it's not that much more than the 150 and is 2-3 times better. Still, £2000 just to get off the ground? Heavens...
I'll skip the 2500, as I think the Ultra 45 is similarly specified, but with a little more expansion and future-proofing. The starting price isn't that much more than a 1500 either, but rapdily rises.
All these boxes are out of my price range as an individual, and I couldn't really justify an employer buying them either.
The more powerful boxes are better value, but you have to pay for the privilege.
As far as I'm concerned, a reasonable entry-level box would be something like the SB1500, at about £1000 or so. Doesn't have to be fancy, but XVR-100 graphics and 512M memory minimum.
There's a similar story when it comes to sparc servers. Sun still sell the V100 and V120. OK, so there's a good market, and these machines have their uses. And they don't have much competition - there aren't many other machines of that low a spec out there.
At least with servers you definitely get into value-for-money territory as you move up the range. Certainly any of the T1 (Niagara) boxes are awesome. But there isn't much value in the sub £5000 space. Again, something like a V100 but with a modern US-IIIi processor at just over the £1000 mark would be handy.
The whole sparc low-end lineup looks incredibly stale. Even the Ultra 45 isn't much more than a SB2500 rehash (a good rehash, but still a rehash).
As might be expected, there's more in the Opteron world down at the low end. You can't really quarrel with the X2100 and Ultra 20.
But even here, Sun make it hard to get something decent. The problem (and this afflicts the whole of the range) is the lack of configuration choice. They seem to make the basic assumption that there's a cheap and nasty option that has the minimum of everything, then have another option in which most things are upgraded, and maybe another option in which everything is maxed out. That's not what I want. I don't want to have to pay for a fancy graphics card just to get a faster cpu, or the other way round. And sometimes I might actually want the base system with a 250G drive. Most PC vendors I look at allow you to select the various components of the system independently, so that I can put together a system that's balanced to meet my needs, but Sun won't let me do that.
Java DTrace
Stephen Lau announced the latest nightly OpenSolaris delivery. Looking through the changelog, I noticed:
Yay! Getting to DTrace from Java!
Issues Resolved:
PSARC case 2006/054 : DTrace JNI Binding
BUG/RFE:6384263PSARC 2006/054 DTrace JNI Binding
Yay! Getting to DTrace from Java!
Monday, February 13, 2006
Evil JES Installer
I'm a glutton for punishment. Must be. I can't think of any other reason why I put myself through this.
I'm testing out the Java Enterprise System. Version 2005Q4 comes in the DVD kit with Solaris 10 Update 1, so I thought I would try that out, following these sample instructions.
The installer starts off OK, but then it complains that J2SE is obsolete. Say what? This is a brand new S10U1 install, and has a newer JDK than is supplied on the JES media. I selected manual upgrade (promising that I would upgrade it myself) in the hope that it wouldn't do anything stupid.
For what it's worth, Solaris 10 Update 1 ships with J2SE 5.0_06, while the JES media contains the older (and insecure) 5.0_04. There are two major issues here already:
So I plug through the screens. (There's another one where it complains about the versions of JATO, JAXP, and JAF being out of date. Why? This is the latest all-singing all-dancing version of Solaris, hot off the press. Why aren't those components up to date?)
So I get to the end and tell it to go install. And what does it do? It downgrades the system Java to the old insecure version!
Aaaaarrrrrrgggggghhhhhh!!!!!!
This is plain bad behaviour, compounding its previous errors with a heinous crime.
I'm testing out the Java Enterprise System. Version 2005Q4 comes in the DVD kit with Solaris 10 Update 1, so I thought I would try that out, following these sample instructions.
The installer starts off OK, but then it complains that J2SE is obsolete. Say what? This is a brand new S10U1 install, and has a newer JDK than is supplied on the JES media. I selected manual upgrade (promising that I would upgrade it myself) in the hope that it wouldn't do anything stupid.
For what it's worth, Solaris 10 Update 1 ships with J2SE 5.0_06, while the JES media contains the older (and insecure) 5.0_04. There are two major issues here already:
- JES ought to have its java version in sync with the version of the OS it's shipped with
- It ought to detect a newer version and accept it as good
So I plug through the screens. (There's another one where it complains about the versions of JATO, JAXP, and JAF being out of date. Why? This is the latest all-singing all-dancing version of Solaris, hot off the press. Why aren't those components up to date?)
So I get to the end and tell it to go install. And what does it do? It downgrades the system Java to the old insecure version!
Aaaaarrrrrrgggggghhhhhh!!!!!!
This is plain bad behaviour, compounding its previous errors with a heinous crime.
Friday, February 10, 2006
JKstat updated
I've updated JKstat - my Java JNI interface to Solaris kstats.
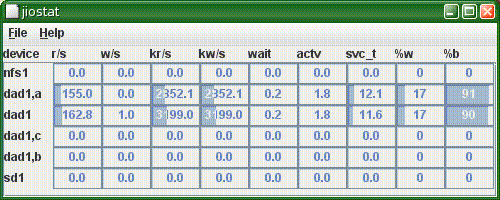
This version adds jiostat, a graphical version of iostat. This is just a basic hack at the problem - I want to be able to select and hide statistics, sort by output, and connect associated statistics (such as a disk with its partitions, or a metadevice with its components). However, the first implementation had pretty awful performance, which is why version 0.09 got skipped.

This version adds jiostat, a graphical version of iostat. This is just a basic hack at the problem - I want to be able to select and hide statistics, sort by output, and connect associated statistics (such as a disk with its partitions, or a metadevice with its components). However, the first implementation had pretty awful performance, which is why version 0.09 got skipped.
Thursday, February 09, 2006
Why do arrays have even numbers of disks?
Like it says: Why do arrays have even numbers of disks?
Most hardware disk arrays - certainly the ones that Sun sell - currently have an even number of drives in them. The StorEdge 3x00 series have 12, while the 6130 has 14.
The problem I have is that if you take away one drive to act as a hot spare, you're then left with 11 or 13. Not only is this an odd number, it's also prime.
So, what sort of sensible grouping of the drives can you come up with? I often punt and simply create a huge raid-5 volume spanning all the drives I've got left, which is simple. But there are cases when I really want to configure 2 identical sets of disks - either to mirror or to give to 2 hosts. To make this work, I have one drive left over (so I use it as a second hot spare).
Wouldn't it be neat to add an extra drive?
Most hardware disk arrays - certainly the ones that Sun sell - currently have an even number of drives in them. The StorEdge 3x00 series have 12, while the 6130 has 14.
The problem I have is that if you take away one drive to act as a hot spare, you're then left with 11 or 13. Not only is this an odd number, it's also prime.
So, what sort of sensible grouping of the drives can you come up with? I often punt and simply create a huge raid-5 volume spanning all the drives I've got left, which is simple. But there are cases when I really want to configure 2 identical sets of disks - either to mirror or to give to 2 hosts. To make this work, I have one drive left over (so I use it as a second hot spare).
Wouldn't it be neat to add an extra drive?
Roundup
Rounding up a few loose ends:
The OpenSolaris Visual Panels project has now started. This really interesting stuff, especially from my viewpoint of developing SolView and JKstat. I agree with JC Van Nieuwenhoven's comment - that managing Solaris with a GUI is a pain - and it's good to see efforts underway to fix this.
(One thing I would say, though, is that good GUIs aren't just for novices. While I might know the 16 arcane commands to configure something, would I rather have a good gui and press 1 button? If it was a good gui, yes!)
Following on from my application profiling to see if a T2000 would be a good thing, I found this article that explains a little bit more about what sorts of behaviour might throw off the statistics. Based on this, I think my machine is spending a lot of time in memcpy.
I also notice that the Ultra 45 workstation lists a 146G SAS drive as an option. I can't see this on the published price lists for the X4x00 or the T2000, but I hope it's on its way as it would help address one of the problem areas I've been having for a while.
The OpenSolaris Visual Panels project has now started. This really interesting stuff, especially from my viewpoint of developing SolView and JKstat. I agree with JC Van Nieuwenhoven's comment - that managing Solaris with a GUI is a pain - and it's good to see efforts underway to fix this.
(One thing I would say, though, is that good GUIs aren't just for novices. While I might know the 16 arcane commands to configure something, would I rather have a good gui and press 1 button? If it was a good gui, yes!)
Following on from my application profiling to see if a T2000 would be a good thing, I found this article that explains a little bit more about what sorts of behaviour might throw off the statistics. Based on this, I think my machine is spending a lot of time in memcpy.
I also notice that the Ultra 45 workstation lists a 146G SAS drive as an option. I can't see this on the published price lists for the X4x00 or the T2000, but I hope it's on its way as it would help address one of the problem areas I've been having for a while.
Tuesday, February 07, 2006
Should I get a T2000?
So I'm looking at the new Sun T2000 boxes, and I tried the test program to see if my workload is suitable.
Now, this is a web server. That's all it does. And it's running coldfusion (ie JRun, as in Java), and Oracle, so first thoughts are that it should match pretty well. So I give pfp a whirl.
That's not good!
OK, so that was an isolated incident. But this machine tends to stick at about the 1.5% grey area. This is typical:
Now, what I don't know is whether there's something odd about this machine, or Oracle, or Coldfusion, or the CMS sitting atop it, or the versions (oldish), or something about the fact that this is an old V880 running an old version of Solaris that pfp can't handle properly. But in any case, the T2000 doesn't look like a given.
I also tried looking at one of the machines I built myself recently, with an Apache/Tomcat/Postgres combo:
That's what I expected. (And I get the same sort of thing on one of my Domino boxes.)
So I'm still unclear as to whether a T2000 would be a good bet for the old webserver.
Now, this is a web server. That's all it does. And it's running coldfusion (ie JRun, as in Java), and Oracle, so first thoughts are that it should match pretty well. So I give pfp a whirl.
# /var/tmp/pfp -p 10
We observed 407247665 instructions separated
in 11.17% floating point and 88.83% others.
This workload is not recommended for UltraSPARC T1 systems.
That's not good!
OK, so that was an isolated incident. But this machine tends to stick at about the 1.5% grey area. This is typical:
# /var/tmp/pfp -p 10
We observed 1960035483 instructions separated
in 1.61% floating point and 98.39% others.
This workload is a potential fit for UltraSPARC T1 systems
and need to be tested.
Now, what I don't know is whether there's something odd about this machine, or Oracle, or Coldfusion, or the CMS sitting atop it, or the versions (oldish), or something about the fact that this is an old V880 running an old version of Solaris that pfp can't handle properly. But in any case, the T2000 doesn't look like a given.
I also tried looking at one of the machines I built myself recently, with an Apache/Tomcat/Postgres combo:
# /var/tmp/pfp 60
We observed 2132762256 instructions separated
in 0.05% floating point and 99.95% others.
This workload is recommended for UltraSPARC T1 systems.
That's what I expected. (And I get the same sort of thing on one of my Domino boxes.)
So I'm still unclear as to whether a T2000 would be a good bet for the old webserver.
Sunday, February 05, 2006
Solaris Info Viewer
Following a discussion on the sysadmin-discuss list, I've put up SolView, a utility I put together a year or so back and then forgot about.
The idea is to have a single window that gets you to the important information about a Solaris system quickly and easily. It hasn't been extensively tested, and relies on Solaris 10 at the present time. Comments etc, especially suggestions for new capabilities or information it could display, are welcome.
The idea is to have a single window that gets you to the important information about a Solaris system quickly and easily. It hasn't been extensively tested, and relies on Solaris 10 at the present time. Comments etc, especially suggestions for new capabilities or information it could display, are welcome.
Friday, February 03, 2006
Suspend/Resume
After my recent confession, and looking at start up time, I tried suspend/resume to see if that could get the system going any quicker.
Now, I had earlier problems with suspend/resume taking forever, so I tried again after updating to S10U1.
And, OK, so the resume is quicker than it was. But it's still about 3 minutes - just the same as a cold boot. There has to be something wrong here - resume should be quicker, as it just has to bring things back into memory and set them running again without having to go through the thinking step of how they got there.
Now, I had earlier problems with suspend/resume taking forever, so I tried again after updating to S10U1.
And, OK, so the resume is quicker than it was. But it's still about 3 minutes - just the same as a cold boot. There has to be something wrong here - resume should be quicker, as it just has to bring things back into memory and set them running again without having to go through the thinking step of how they got there.
Thursday, February 02, 2006
System start up time
To follow on from why I use windows, I just did some (unscientific) start-up timings on my SunBlade 1500 running Solaris 10 Update 1.
Time in seconds from pressing the on button:
There's a 30 second hole in the middle where I'm typing in my username and password (and writing down the numbers) where 10 seconds would be more reasonable, so the full length of time to actual login is almost exactly 3 minutes. (And then another 20 seconds to open Mozilla.)
(I've broken the graphical startup into 2 phases, dtlogin start and JDS start, with the human typing in the middle. The whole graphical login process takes about a minute of the 3, with the general boot taking the other 2 minutes. OK, so it's possible to make the gui startup much quicker, but there's still the whole hardware phase and kernel boot to get past.)
What's the machine been doing all this time? A quick look at iostat immediately afterwards:
Or in raw terms from kstat:
So during boot I read 125M of data off the disk, in 11,000 reads. And this actually only covers about 2/3 of the boot - it isn't until about a minute into the boot that the kstats are created. If you allow for the login delay while I'm typing username and password and the few seconds it takes to actually run the above commands, and you can see that the disk is actually well over 50% busy during the boot. Based on the disk activity, boot times can't improve by better than a factor of 2 unless the disk access pattern changes (larger reads than the average 11k seen here would help).
The cpu statistics can also be obtained:
Remember that these numbers don't cover the first 1/3 of the boot. (And they don't add up, either, as I make that 170s which is more than the 140s between crtime and snaptime.) But looking at it, the processor is less than 50% busy.
I'm not sure how to look at these numbers and convert them into the sort of boot-time improvements that might be made, but taking the 50% resource utilization at face value indicates that the portion of the boot covered by the kstat collection could be sped up by a factor 2, which takes the overall cold start from 3 minutes to 2. That wouldn't be bad, would it?
Time in seconds from pressing the on button:
- Solaris license terms: 41s
- Console Login prompt: 104s
- Desktop Login prompt: 133s
- JDS start: 165s
- JDS ready: 190s
- Terminal ready to type: 199s
There's a 30 second hole in the middle where I'm typing in my username and password (and writing down the numbers) where 10 seconds would be more reasonable, so the full length of time to actual login is almost exactly 3 minutes. (And then another 20 seconds to open Mozilla.)
(I've broken the graphical startup into 2 phases, dtlogin start and JDS start, with the human typing in the middle. The whole graphical login process takes about a minute of the 3, with the general boot taking the other 2 minutes. OK, so it's possible to make the gui startup much quicker, but there's still the whole hardware phase and kernel boot to get past.)
What's the machine been doing all this time? A quick look at iostat immediately afterwards:
extended device statistics
r/s w/s kr/s kw/s wait actv wsvc_t asvc_t %w %b device
74.5 3.5 824.7 37.0 0.3 0.8 4.3 9.7 13 46 c0t0d0
Or in raw terms from kstat:
reads 10986
writes 482
nread 124590592
nwritten 5022208
So during boot I read 125M of data off the disk, in 11,000 reads. And this actually only covers about 2/3 of the boot - it isn't until about a minute into the boot that the kstats are created. If you allow for the login delay while I'm typing username and password and the few seconds it takes to actually run the above commands, and you can see that the disk is actually well over 50% busy during the boot. Based on the disk activity, boot times can't improve by better than a factor of 2 unless the disk access pattern changes (larger reads than the average 11k seen here would help).
The cpu statistics can also be obtained:
cpu_nsec_idle 102634677402
cpu_nsec_kernel 44861276123
cpu_nsec_user 25778566225
Remember that these numbers don't cover the first 1/3 of the boot. (And they don't add up, either, as I make that 170s which is more than the 140s between crtime and snaptime.) But looking at it, the processor is less than 50% busy.
I'm not sure how to look at these numbers and convert them into the sort of boot-time improvements that might be made, but taking the 50% resource utilization at face value indicates that the portion of the boot covered by the kstat collection could be sped up by a factor 2, which takes the overall cold start from 3 minutes to 2. That wouldn't be bad, would it?
Subscribe to:
Posts (Atom)