A new version of my Java SNMP viewer Jangle is now available.
One thing I've wanted to do is automatically build relationships. There are two tabs in the Jangle display that do this automatically, showing Siblings and Cousins.
The Siblings tab shows attributes that share a common parent. Due to the way that SNMP works, this means different instances of the same thing. For example, if you're interested in ifInOctets, then this will have an entry for each interface - ifInOctets.1, ifInOctets.2, ifInOctets.3 and so on. So the Siblings display will put all these on one graph for you.
What if you're just interested in all the attributes of a particular interface? Given ifInOctets.2, you want ifOutOctets.2 and the like? That's where the Cousins tab comes in - it will show (and graph) all these related attributes for you. (Of course, while Cousins is an appropriate term in the sense that the other attributes are children of your parents siblings, it's also only a specific subset of those Cousins. It would be nice to come up with a better term.)
It's relatively trivial to build these relationships automatically - the OID tree is structured to make it possible. They also answer the questions I tend to ask most often. Building more complex relationships will likely have to be done by hand, and require domain-specific knowledge.
This was relatively easy to code up, with just a little twist. When you select a new OID to display, it starts all the graphs from scratch again. What I also wanted to be sure of was that if the new OID was a sibling or cousin of the one already being shown, then it would keep the existing sibling or cousin graph rather than reset it.
Friday, December 03, 2010
Monday, November 22, 2010
KAR at LOSUG
Last Wednesday I gave a short talk about KAR at LOSUG.
Apart from the fact that my laptop and the projector refused to get along, it went OK. That disagreement meant that the interactive show and tell (aka the demo) got skipped, but that was always designed as an extra. I hope I got people thinking - the real aim here is to try and make people think about what we do, rather than spoonfeed solutions to them (that's what marketing is for).
For the talk I released a new version of KAR, and in preparing the talk and getting some things ready I stumbled across one or two issues I thought worthy of further fixes.
Part of this is my implementation, but using JKstat to parse the KAR archives has never been exactly quick. Several minutes for a full day's data from a decent server. My original implementation of graph generation involved doing that for every graph - so generating the 100+ graphs took rather a long time.
Here follows a completely gratuitous graph: network traffic on my home machine over the course of a day.

The parser in JKstat was only partially finished, so I tidied it up a bit. It now caches parsed data, and allows consumers to step backwards as well as forwards, and rewind, and the cache is shared across multiple instances. This allows you to just parse the data once and then analyze it to your heart's content. What this means is that generating all the graphs takes only a little longer than generating the first one - making it 100 times faster.
(Which proves the point: fixing truly stupid implementations can give you huge performance gains. There is no way I can imagine getting a hundred-fold performance improvement by tweaking the parser. That's not to say I'm happy with performance now - far from it - but it's made one particular common task viable, which it wasn't before.)
So, a new release of both KAR and JKstat is now available.
The next step for KAR is to identify additional measurements that would be generally useful, and then add them to the list of graphs generated (and maybe have specific utilities for specific data).
Apart from the fact that my laptop and the projector refused to get along, it went OK. That disagreement meant that the interactive show and tell (aka the demo) got skipped, but that was always designed as an extra. I hope I got people thinking - the real aim here is to try and make people think about what we do, rather than spoonfeed solutions to them (that's what marketing is for).
For the talk I released a new version of KAR, and in preparing the talk and getting some things ready I stumbled across one or two issues I thought worthy of further fixes.
Part of this is my implementation, but using JKstat to parse the KAR archives has never been exactly quick. Several minutes for a full day's data from a decent server. My original implementation of graph generation involved doing that for every graph - so generating the 100+ graphs took rather a long time.
Here follows a completely gratuitous graph: network traffic on my home machine over the course of a day.

The parser in JKstat was only partially finished, so I tidied it up a bit. It now caches parsed data, and allows consumers to step backwards as well as forwards, and rewind, and the cache is shared across multiple instances. This allows you to just parse the data once and then analyze it to your heart's content. What this means is that generating all the graphs takes only a little longer than generating the first one - making it 100 times faster.
(Which proves the point: fixing truly stupid implementations can give you huge performance gains. There is no way I can imagine getting a hundred-fold performance improvement by tweaking the parser. That's not to say I'm happy with performance now - far from it - but it's made one particular common task viable, which it wasn't before.)
So, a new release of both KAR and JKstat is now available.
The next step for KAR is to identify additional measurements that would be generally useful, and then add them to the list of graphs generated (and maybe have specific utilities for specific data).
Thursday, October 28, 2010
AfterStep, piewm, tvtwm, and friends
Following on from earlier work, I've made available some AfterStep packages for Solaris.
Then, I tried some of the twm variants. I started with ctwm and vtwm, and then moved on to tvtwm and piewm. Then I hit a problem - piewm didn't work. It was choking somewhere in the lex parser, so refusing to load any config, so no menus or anything. It's based on a older version of tvtwm and, rather than attempt to learn lex and fix that, I had a go at simply adding the pie menu support to the latest version of tvtwm (tvtwm-pl11), and that turned out to be pretty easy.
So my merged source, boringly named ptvtwm, is available from here, as are the usual Solaris packages. The packages include piewm and tvtwm derived from ptvtwm, as well as ctwm and vtwm, along with a private copy of xli so that tvtwm/piewm can load a background picture.
That's quite a lot of Window managers, so I've put together a list of package window managers.
That's essentially it for now. I'm hoping to get Xfce packaged up, but there are a fair number of prerequisites that Solaris doesn't have (or has antiquated versions of) so the packages end up being pretty huge. I'll get there, but haven't yet got a build I'm happy to let out.
Then, I tried some of the twm variants. I started with ctwm and vtwm, and then moved on to tvtwm and piewm. Then I hit a problem - piewm didn't work. It was choking somewhere in the lex parser, so refusing to load any config, so no menus or anything. It's based on a older version of tvtwm and, rather than attempt to learn lex and fix that, I had a go at simply adding the pie menu support to the latest version of tvtwm (tvtwm-pl11), and that turned out to be pretty easy.
So my merged source, boringly named ptvtwm, is available from here, as are the usual Solaris packages. The packages include piewm and tvtwm derived from ptvtwm, as well as ctwm and vtwm, along with a private copy of xli so that tvtwm/piewm can load a background picture.
That's quite a lot of Window managers, so I've put together a list of package window managers.
That's essentially it for now. I'm hoping to get Xfce packaged up, but there are a fair number of prerequisites that Solaris doesn't have (or has antiquated versions of) so the packages end up being pretty huge. I'll get there, but haven't yet got a build I'm happy to let out.
Thursday, October 21, 2010
Old and New
A couple of window managers packaged up for Solaris this week.
First, some solaris packages for the pekwm window manager. This pretty much scores a bullseye when it comes to minimalism, and is still being developed.
Go back 20 years, and I've built some awm packages. Now the Ardent Window Manager wasn't the first I ever used, but I spent about 2 years working with it, and it was pretty good. Highly flexible and customizable, in the true style of the time - you open up the config file in your favourite editor and make it do whatever you want.
Now, I had to make a tiny number of code changes to get it to compile, but only a tiny number, and all pretty trivial. And it works just fine, even if it does have a bit of a retro look to it.
First, some solaris packages for the pekwm window manager. This pretty much scores a bullseye when it comes to minimalism, and is still being developed.
Go back 20 years, and I've built some awm packages. Now the Ardent Window Manager wasn't the first I ever used, but I spent about 2 years working with it, and it was pretty good. Highly flexible and customizable, in the true style of the time - you open up the config file in your favourite editor and make it do whatever you want.
Now, I had to make a tiny number of code changes to get it to compile, but only a tiny number, and all pretty trivial. And it works just fine, even if it does have a bit of a retro look to it.
Thursday, October 14, 2010
Enlightenment packages for Solaris
As I mentioned earlier when talking about Window Maker, I've been hoping to find time to get some other window managers packaged up for Solaris.
OK, so Enlightenment packages are available. Just to be clear, these are e16, not some cut of the current development branch. (I'm having a look at the EFL beta, trying to get it to work on Solaris.)
As with wmaker, these packages should install fine on Solaris 10 (some reasonably current update, anyway) and OpenSolaris/OpenIndiana. They should appear as session options on the login screen, and they should basically work. But this isn't something I use extensively, and there are almost certainly rough edges.
The packages include imlib2, e16, libast, Eterm, and themes. They all go together, so there's just the one package. This all installs directly into /usr, which is fine as there aren't any conflicts with anything that ships with Solaris.
While I like playing with shiny toys such as enlightenment, I never really got on with it - the behaviour was always slightly interesting, and I found the themes overly fussy, And speaking of themes, a whole bunch of themes for e16 are available, and a lot of those are quite polished.
OK, so Enlightenment packages are available. Just to be clear, these are e16, not some cut of the current development branch. (I'm having a look at the EFL beta, trying to get it to work on Solaris.)
As with wmaker, these packages should install fine on Solaris 10 (some reasonably current update, anyway) and OpenSolaris/OpenIndiana. They should appear as session options on the login screen, and they should basically work. But this isn't something I use extensively, and there are almost certainly rough edges.
The packages include imlib2, e16, libast, Eterm, and themes. They all go together, so there's just the one package. This all installs directly into /usr, which is fine as there aren't any conflicts with anything that ships with Solaris.
While I like playing with shiny toys such as enlightenment, I never really got on with it - the behaviour was always slightly interesting, and I found the themes overly fussy, And speaking of themes, a whole bunch of themes for e16 are available, and a lot of those are quite polished.
Tuesday, October 12, 2010
Remote Monitoring, APIs, and JMX
Recently I went along to the Cambridge Java Group. Enjoyable evening - would be great to get more people along, so if there's anybody else in Cambridge interested in Java and related technologies then do come along!
I talked about JKstat briefly, and I hope that some people found it interesting. One of the comments was along the lines of "hey, you could expose this with JMX and monitor it remotely". I had looked at JMX before, and had largely ignored it because I couldn't see an easy way to use the technology. So I tried again, putting together a bean interface and implementation, and a simple server.
I pointed jconsole at it, and it works. I can see the data I exposed there in jconsole. So, that proves that my code works. But is that it? After all, jconsole can do some quite sophisticated monitoring of a JVM, and give pretty graphs. But there seems to be a fair amount of domain-specific knowledge that has gone into that, which is hard-coded into the client. And I really don't want to write (yet another) client interface - the whole point is to leverage what is claimed to be considerable investment in JMX tooling.
This investment must be kept locked safely away. I've had a look around, and really can't see much in the way of fully functional general-purpose JMX clients. (Here's a list.)
Of course, I've been here before. I ended up writing my own SNMP client because I couldn't find anything else that did what I wanted. I really don't want to do the same for JMX.
So, a question: what do people use for monitoring that uses JMX? How valuable is it?
Of course, you wouldn't actually set up a JMX server and client specifically for accessing JKstat. That would be silly. After all, JKstat comes with a fully functional client-server mode that exposes all the data you need in a reasonably efficient manner. The ideal case for using JMX would be when you had an existing system already being monitored with JMX, at which point you could simply add JKstat support to gain access to extra data without adding additional protocols or tools.
I've also been looking at other client-server technologies. One that I'll probably do (partly because it shares some framework with JMX, partly because I know how to do it anyway) is RMI. But that, like JMX, is fairly specific to Java. It would be nice to have something that was capable of communicating with, say, python (or pretty much any scripting language). You would have thought that because I had used XML-RPC then I would be able to access it from anything else using XML-RPC, but that's not the case. I needed to use extensions to get sensible type support (like the fact that much of the data is stored as a long not an int), and those aren't commonly deployed. I was, therefore, intrigued by Theo's rant which summed up my thoughts exactly, and saved me the trouble of investigating JSON, as it's clearly not up to the task either.
So many half-baked answers. Go on, somebody - tell me what I'm missing!
I talked about JKstat briefly, and I hope that some people found it interesting. One of the comments was along the lines of "hey, you could expose this with JMX and monitor it remotely". I had looked at JMX before, and had largely ignored it because I couldn't see an easy way to use the technology. So I tried again, putting together a bean interface and implementation, and a simple server.
I pointed jconsole at it, and it works. I can see the data I exposed there in jconsole. So, that proves that my code works. But is that it? After all, jconsole can do some quite sophisticated monitoring of a JVM, and give pretty graphs. But there seems to be a fair amount of domain-specific knowledge that has gone into that, which is hard-coded into the client. And I really don't want to write (yet another) client interface - the whole point is to leverage what is claimed to be considerable investment in JMX tooling.
This investment must be kept locked safely away. I've had a look around, and really can't see much in the way of fully functional general-purpose JMX clients. (Here's a list.)
Of course, I've been here before. I ended up writing my own SNMP client because I couldn't find anything else that did what I wanted. I really don't want to do the same for JMX.
So, a question: what do people use for monitoring that uses JMX? How valuable is it?
Of course, you wouldn't actually set up a JMX server and client specifically for accessing JKstat. That would be silly. After all, JKstat comes with a fully functional client-server mode that exposes all the data you need in a reasonably efficient manner. The ideal case for using JMX would be when you had an existing system already being monitored with JMX, at which point you could simply add JKstat support to gain access to extra data without adding additional protocols or tools.
I've also been looking at other client-server technologies. One that I'll probably do (partly because it shares some framework with JMX, partly because I know how to do it anyway) is RMI. But that, like JMX, is fairly specific to Java. It would be nice to have something that was capable of communicating with, say, python (or pretty much any scripting language). You would have thought that because I had used XML-RPC then I would be able to access it from anything else using XML-RPC, but that's not the case. I needed to use extensions to get sensible type support (like the fact that much of the data is stored as a long not an int), and those aren't commonly deployed. I was, therefore, intrigued by Theo's rant which summed up my thoughts exactly, and saved me the trouble of investigating JSON, as it's clearly not up to the task either.
So many half-baked answers. Go on, somebody - tell me what I'm missing!
Saturday, October 02, 2010
Window Maker
I've always experimented with different X11 window managers and desktops. There was a time when there was actually significant choice and variety, and a lot of energy to go with it.
I simply never got on with either SunView or OpenWindows, much preferring awm or tvtwm. And while CDE had some useful utilities, the desktop itself drove me to distraction. I appreciate the strengths of KDE, but can't get on with it either. I currently use either the Solaris JDS build of GNOME or a home-built version of XFCE as my primary desktop.
I spend a lot of my time living inside VNC sessions, and there I run Window Maker. I've always liked Window Maker - fast, lightweight, and there were oodles of themes available. (A theme here is a desktop background and a colour scheme for menus and window decorations.) Unfortunately availability of themes is now limited.
I've made available my own Window Maker Packages for Solaris. These include the software and integration with either dtlogin or gdm, and will work on either Solaris 10 or OpenSolaris/OpenIndiana.
Included in those packages are a couple of simple themes I've put together based on OpenSolaris and OpenIndiana, which you can also get directly from the above link if you already have Window Maker running.
I also run, at times, many of the other older styles of window managers, from the basic twm derivatives up to enlightenment and AfterStep. Hopefully I'll be able to find some time to get those properly packaged up as well.
I simply never got on with either SunView or OpenWindows, much preferring awm or tvtwm. And while CDE had some useful utilities, the desktop itself drove me to distraction. I appreciate the strengths of KDE, but can't get on with it either. I currently use either the Solaris JDS build of GNOME or a home-built version of XFCE as my primary desktop.
I spend a lot of my time living inside VNC sessions, and there I run Window Maker. I've always liked Window Maker - fast, lightweight, and there were oodles of themes available. (A theme here is a desktop background and a colour scheme for menus and window decorations.) Unfortunately availability of themes is now limited.
I've made available my own Window Maker Packages for Solaris. These include the software and integration with either dtlogin or gdm, and will work on either Solaris 10 or OpenSolaris/OpenIndiana.
Included in those packages are a couple of simple themes I've put together based on OpenSolaris and OpenIndiana, which you can also get directly from the above link if you already have Window Maker running.
I also run, at times, many of the other older styles of window managers, from the basic twm derivatives up to enlightenment and AfterStep. Hopefully I'll be able to find some time to get those properly packaged up as well.
Thursday, September 30, 2010
SolView 0.54
Actually, this was supposed to be about version 0.53 of SolView, but 0.54 has the fixed JProc which is quite handy.
Apart from that bugfix, SolView now sports a number of useful refinements.
The localprofile subcommand generates a jumpstart profile that will (approximately) match the current system. So on my desktop:
Actually, there's a little bit missing from the above, which is what another new subcommand - missingpackages - will show, namely the list of packages that should be installed to meet dependency requirements but aren't:
Now, some of those are install errors on my part (I ought to have killed all the postgres packages), but some are just due to wrong dependency data.
Continuing a bit of a theme, disks, networks interfaces, processors, packages, and clusters are sorted.
In the jumpstart profile builder there's quite a lot more polish. Version 0.52 added automatic recursive removal of packages, but the new version fixes a number of minor display issues - the checkboxes update instantly, clusters properly reflect their status if all their constituent packages are added or removed, and the profile appears automatically when you go to the profile display tab. And if you're fed up, you can start over without exiting. All in all it's now much easier to use.
Apart from that bugfix, SolView now sports a number of useful refinements.
The localprofile subcommand generates a jumpstart profile that will (approximately) match the current system. So on my desktop:
# ./solview localprofile
cluster SUNWCXall
cluster SUNWCapache delete
cluster SUNWCapch2 delete
cluster SUNWCappserver delete
cluster SUNWCbreg delete
cluster SUNWCfsmgt delete
cluster SUNWCiq delete
cluster SUNWCmcdk delete
cluster SUNWCmip delete
cluster SUNWCnet delete
cluster SUNWCpcmc delete
cluster SUNWCpgadmin3 delete
cluster SUNWCpmgr delete
cluster SUNWCpostgr delete
cluster SUNWCpostgr-82 delete
cluster SUNWCpostgr-82-dev delete
cluster SUNWCpostgr-83 delete
cluster SUNWCpostgr-83-dev delete
cluster SUNWCpostgr-dev delete
cluster SUNWCrm delete
cluster SUNWCservicetags delete
cluster SUNWCsip delete
cluster SUNWCsmap delete
cluster SUNWCsmc delete
cluster SUNWCsppp delete
cluster SUNWCswup delete
cluster SUNWCtcat delete
cluster SUNWCwbem delete
cluster SUNWCwsdk delete
cluster SUNWCxmft delete
cluster SUNWCzebra delete
package SK98sol delete
package SKfp delete
package SUNWast delete
package SUNWcnsr delete
package SUNWcnsu delete
package SUNWfac delete
package SUNWfwdc delete
package SUNWfwdcu delete
package SUNWipplr delete
package SUNWipplu delete
package SUNWjato delete
package SUNWjatodmo delete
package SUNWjatodoc delete
package SUNWjsnmp delete
package SUNWluzone delete
package SUNWlvma delete
package SUNWlvmg delete
package SUNWmcon delete
package SUNWmcos delete
package SUNWmcosx delete
package SUNWmctag delete
package SUNWosdem delete
package SUNWpdas delete
package SUNWrmwbr delete
package SUNWrmwbu delete
package SUNWsra delete
package SUNWsrh delete
package SUNWtnamd delete
package SUNWtnamr delete
package SUNWtnetd delete
package SUNWtnetr delete
package SUNWwbpro delete
package SUNWwebminr delete
package SUNWwebminu delete
package SUNWxorg-compatlinks delete
package SUNWxwslb delete
package SUNWzfsgr delete
package SUNWzfsgu delete
Actually, there's a little bit missing from the above, which is what another new subcommand - missingpackages - will show, namely the list of packages that should be installed to meet dependency requirements but aren't:
# ./solview missingpackages
missing package SUNW5xmft needed by [SUNW5xfnt, SUNWjxplt, SUNWhkfnt]
missing package SUNWcxmft needed by [SUNWcxfnt, SUNWcscgu, SUNWjxplt]
missing package SUNWfsmgtr needed by [SUNWdmgtr, SUNWdmgtu]
missing package SUNWfsmgtu needed by [SUNWdmgtr, SUNWdmgtu]
missing package SUNWjxmft needed by [SUNWjxcft, SUNWjedt, SUNWjxplt]
missing package SUNWkxmft needed by [SUNWkuxft, SUNWjxplt]
missing package SUNWluzone needed by [SUNWzoneu]
missing package SUNWlvma needed by [SUNWlvmr, SUNWmddr]
missing package SUNWpostgr-82-client needed by [SUNWpostgr-upgrade]
missing package SUNWpostgr-82-libs needed by [SUNWpmdbdpg, SUNWpostgr-upgrade]
missing package SUNWpostgr-82-server needed by [SUNWpostgr-upgrade]
missing package SUNWwbcor needed by [SUNWdmgtu]
missing package SUNWwbcou needed by [SUNWdhcsu, SUNWdmgtu]
missing package SUNWwbpro needed by [SUNWdmgtu]
missing package SUNWzlibr needed by [openofficeorg-ure]
Now, some of those are install errors on my part (I ought to have killed all the postgres packages), but some are just due to wrong dependency data.
Continuing a bit of a theme, disks, networks interfaces, processors, packages, and clusters are sorted.
In the jumpstart profile builder there's quite a lot more polish. Version 0.52 added automatic recursive removal of packages, but the new version fixes a number of minor display issues - the checkboxes update instantly, clusters properly reflect their status if all their constituent packages are added or removed, and the profile appears automatically when you go to the profile display tab. And if you're fed up, you can start over without exiting. All in all it's now much easier to use.
JProc 0.5
I've just released version 0.5 of JProc, which allows you to access Solaris data from java applications.
I was hoping for a few more features, but encountered a fairly nasty bug, and it was more than worth fixing that straight away.
Basically, you get the data from /proc by opening files in the /proc filesystem and reading data from them. I was doing the open(), but there was a distinct lack of close() associated with each one. A massive file descriptor leak ensued.

The one neat feature that made it was the ability to select which columns are visible in the process viewer. This involved a little fiddling with the Model underlying the JTable. Essentially, all I had to do was add an array of visible columns, each element of which maps to a real column. So I can have only some of the columns visible, and could re-order them if that's desired. The only tricky bit I had trouble with is that I have custom renderers for some of the columns (so that times and sizes are shown in human-friendly terms), and fiddling with the columns completely lost the custom renderers, forcing me to have to re-apply the renderers any time I change the structure.
I've hidden a few of the less commonly used columns by default, which helps by making the viewer less cluttered. There's still room for improvement, especially in the area of aggregation and filtering - areas where top and prstat are so-so.
I was hoping for a few more features, but encountered a fairly nasty bug, and it was more than worth fixing that straight away.
Basically, you get the data from /proc by opening files in the /proc filesystem and reading data from them. I was doing the open(), but there was a distinct lack of close() associated with each one. A massive file descriptor leak ensued.
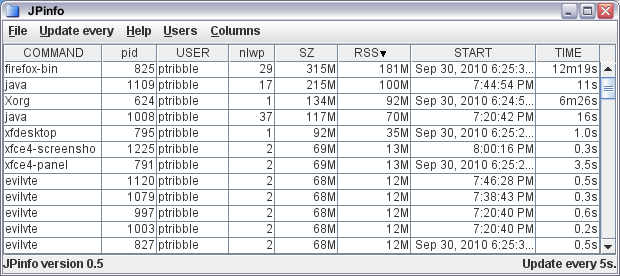
The one neat feature that made it was the ability to select which columns are visible in the process viewer. This involved a little fiddling with the Model underlying the JTable. Essentially, all I had to do was add an array of visible columns, each element of which maps to a real column. So I can have only some of the columns visible, and could re-order them if that's desired. The only tricky bit I had trouble with is that I have custom renderers for some of the columns (so that times and sizes are shown in human-friendly terms), and fiddling with the columns completely lost the custom renderers, forcing me to have to re-apply the renderers any time I change the structure.
I've hidden a few of the less commonly used columns by default, which helps by making the viewer less cluttered. There's still room for improvement, especially in the area of aggregation and filtering - areas where top and prstat are so-so.
Monday, September 06, 2010
KAR 0.4
The latest release of KAR, the Kstat Activity Reporter, is now available.
This version adds a couple of extra features:
The graphs subcommand will generate a bunch of useful png graphs for a given input file. Currently, I generate basic graphs for cpu utilization (user/kernel/idle for the whole system and for each cpu), I/O, and network statistics.
I've also added a simple browser, which looks for kar output files and lets you load them into either the kstat browser or chart builder from JKstat.
Oh, and in line with some of the other work I've been doing recently, most of the output is sorted correctly.
This version adds a couple of extra features:
The graphs subcommand will generate a bunch of useful png graphs for a given input file. Currently, I generate basic graphs for cpu utilization (user/kernel/idle for the whole system and for each cpu), I/O, and network statistics.
I've also added a simple browser, which looks for kar output files and lets you load them into either the kstat browser or chart builder from JKstat.
Oh, and in line with some of the other work I've been doing recently, most of the output is sorted correctly.
Sunday, September 05, 2010
JKstat 0.41
Updated versions of JKstat are coming out more frequently than I would like at the moment. I think I'm done and move on to something else and find I need to add some new feature.
Having just finished 0.40, which implemented Comparable to make sorting easier, I went through more of the code - including the demos included, and those in SolView - to look at how they sorted (or, in some cases, failed to sort where they should have) their output. This led me to make a slight change to the jkstat api, which cleaned up a little of the code.
The data stored by a Kstat is a simple key-value hash.The original implementation exposed this internal data structure - you simply got access to the internal Java
This version also includes a couple of samples using JStripChart, as shown in an earlier blog entry
Having just finished 0.40, which implemented Comparable to make sorting easier, I went through more of the code - including the demos included, and those in SolView - to look at how they sorted (or, in some cases, failed to sort where they should have) their output. This led me to make a slight change to the jkstat api, which cleaned up a little of the code.
The data stored by a Kstat is a simple key-value hash.The original implementation exposed this internal data structure - you simply got access to the internal Java
Map. This always felt slightly ugly, exposing internal implementation details. So that's been changed. There's a new Kstat.statistics() method, which simply returns a Set of the statistic names. This is really what clients want, rather than getting the hash and getting its keys, which is what they did before. Furthermore, in almost every case you want the list of statistic names to be sorted, so rather than everyone getting the list and sorting it themselves, it's backed by a TreeSet and is already sorted. The original getMap() method is gone. Removed. That's why we're not yet at version 1.This version also includes a couple of samples using JStripChart, as shown in an earlier blog entry
Wednesday, September 01, 2010
Simple Java strip charts
I've been looking for a very simple Java strip chart for a while, and haven't found one. So in the end I decided to put together something myself, the end result being JStripChart.
(There's already something else out there called jstripchart. Just to confuse you, it's a python implementation.)
Using JKstat to knock something together I came up with this:

Of course, you partly miss the point which is that this thing is merrily scrolling away.
I expect to be able to use this fairly extensively in both JKstat and SolView, but it's certainly not tied to those in any way - it's designed to be trivially simple to use in any context.
The API really is very simple. Just create a chart:
which you can add to your application in the normal way as it's just a
will add the value
(There's already something else out there called jstripchart. Just to confuse you, it's a python implementation.)
Using JKstat to knock something together I came up with this:

Of course, you partly miss the point which is that this thing is merrily scrolling away.
I expect to be able to use this fairly extensively in both JKstat and SolView, but it's certainly not tied to those in any way - it's designed to be trivially simple to use in any context.
The API really is very simple. Just create a chart:
JStripChart jsc = new JStripChart();
which you can add to your application in the normal way as it's just a
JPanel, and then
jsc.add(some_data);
will add the value
some_data to the right of the chart and move everything else along. That's it. (To get it to continuously update, create a Timer loop.)
Monday, August 30, 2010
New SolView
I've just released a new version of SolView. This version cleans up the code used to display SVR4 packaging, and makes a couple of improvements to the Jumpstart profile builder.
Nothing earth-shattering, but I made the list of packages and clusters sorted, which makes it a lot easier to find things. And, to make that less necessary, I implemented recursive removal of packages: if you remove a package, it removes anything that depends on that package as well, keeping the package dependency graph self-consistent.
There are various ways to make sorting work, and I had put together a couple of Comparator classes before doing it properly. The proper way is just to
Once Comparable is implemented, then all I need to do is replace
Of course, there's no point in learning something like this and then only using it the once. So there's a new version of JKstat in which the
Nothing earth-shattering, but I made the list of packages and clusters sorted, which makes it a lot easier to find things. And, to make that less necessary, I implemented recursive removal of packages: if you remove a package, it removes anything that depends on that package as well, keeping the package dependency graph self-consistent.
There are various ways to make sorting work, and I had put together a couple of Comparator classes before doing it properly. The proper way is just to
implement Comparable in the classes that need sorting. And in most cases the actual comparison is trivial - we're just comparing the name, which is just a String. (For patches it's a 2-stage numerical comparison of the patch id and revision, but still simple.)Once Comparable is implemented, then all I need to do is replace
Set with TreeSet and everything sorts. Simple, obvious, and something I should have done much earlier.Of course, there's no point in learning something like this and then only using it the once. So there's a new version of JKstat in which the
Kstat class implements Comparable, which immediately gets the output from some of the JKstat demos sorted. (And sorted correctly - there is a specific Comparator in use here, to sort names like sd0 which contain numbers correctly: the numerical part is sorted separately and as a number, so that sd2 comes before sd10.)
Saturday, August 21, 2010
Which snmp on Solaris?
I've just updated Jangle, my java based snmp viewer. Just a presentation tweak: the tree and list now show user-friendly names. For example, ifInOctets rather than 1.3.6.1.2.1.2.2.1.10. (Well, I find it easier to read, anyway!)
To be useful, you actually need to be running snmp on the machine you wish to monitor. Which leads me to a question: on Solaris, do you use the system supplied snmp daemon?
And if you do use the system one, is that just for convenience or do you use any of the extra functionality that it provides?
I know that I simply wipe out all the supplied snmp and sma stuff and put my own build of net-snmp in its place.
To be useful, you actually need to be running snmp on the machine you wish to monitor. Which leads me to a question: on Solaris, do you use the system supplied snmp daemon?
And if you do use the system one, is that just for convenience or do you use any of the extra functionality that it provides?
I know that I simply wipe out all the supplied snmp and sma stuff and put my own build of net-snmp in its place.
Friday, August 20, 2010
A new light
While the world of OpenSolaris has been pretty dark and dismal over the last 6 months, a new light has appeared.
The Illumos project, led by Garrett D'Amore, is bringing the OpenSolaris codebase truly into the open. Initially just the base system (ON - kernel and basic utilities), it will be free of encumbered code and capable of self-hosting.
Illumos itself is just a foundation, not a fully-fledged system. It can be taken by others as a basis for distributions and, indeed, there are already efforts to do so. While it's still early days, it's already about as close to being capable of being used to create an independent distribution as the original OpenSolaris source was.
The initial aim was for Illumos to be fully synchronized with the primary source from Oracle. It seems that Oracle have decided to remove themselves from the community by ceasing to make their code available. Such an ill-considered move hurts only Oracle: it frees the community from doubt, allowing it to move ahead freely, and removes any control that Oracle might have. (And it's clear that one thing that Oracle do want is control, so taking a step that eliminates their ability to control is somewhat strange.)
Elsewhere, Oracle's policy of radio silence towards the OpenSolaris community continues. Again, Oracle are harming themselves here - turning supporters into enemies, contributors into competitors. By working with the community rather than antagonizing it, they could have turned it into an asset. Now the outside energy and support that Oracle could have tapped into is being focused into Illumos and its related projects.
The Illumos project, led by Garrett D'Amore, is bringing the OpenSolaris codebase truly into the open. Initially just the base system (ON - kernel and basic utilities), it will be free of encumbered code and capable of self-hosting.
Illumos itself is just a foundation, not a fully-fledged system. It can be taken by others as a basis for distributions and, indeed, there are already efforts to do so. While it's still early days, it's already about as close to being capable of being used to create an independent distribution as the original OpenSolaris source was.
The initial aim was for Illumos to be fully synchronized with the primary source from Oracle. It seems that Oracle have decided to remove themselves from the community by ceasing to make their code available. Such an ill-considered move hurts only Oracle: it frees the community from doubt, allowing it to move ahead freely, and removes any control that Oracle might have. (And it's clear that one thing that Oracle do want is control, so taking a step that eliminates their ability to control is somewhat strange.)
Elsewhere, Oracle's policy of radio silence towards the OpenSolaris community continues. Again, Oracle are harming themselves here - turning supporters into enemies, contributors into competitors. By working with the community rather than antagonizing it, they could have turned it into an asset. Now the outside energy and support that Oracle could have tapped into is being focused into Illumos and its related projects.
Wednesday, July 14, 2010
Moving OpenSolaris forward
Unless you've been living under a rock for a while, it should be clear that the OpenSolaris Community isn't in the healthiest state. Oracle, as the new owners and sponsors of the project, have been spectacularly uncommunicative. The Governing Board have been left completely powerless, reduced to the role of spectators as Oracle withdraws behind its own barriers and what's left of the external community starts to engage in infighting.
So, and this hasn't been an easy decision, we have resolved:
The OGB is keen to promote the uptake and open development of OpenSolaris and to work on behalf of the community with Oracle, as such the OGB needs Oracle to appoint a liaison by August 16, 2010, who has the authority to talk about the future of OpenSolaris and its interaction with the OpenSolaris community. Otherwise the OGB will take action at the August 23 meeting to trigger the clause in the OGB charter that will return control of the community to Oracle.
Now, and sorry Ben, this isn't a "start talking to us or we'll just shot ourselves in the head" ultimatum. We're already on life support, if there are no signs of life then life support will be turned off.
Continuing on, or waiting indefinitely, merely perpetuates a lie. All is not well, and we would all be foolish to believe that it is. To do so would simply be delusional.
It may be nice for some to think that Oracle will ride up on a white charger to save the day. Even if that were to happen, it wouldn't really change the reality of the situation: that the current state of the community is essentially incompatible with the OpenSolaris charter and constitution, and that we need to move forward to a new organization that has new methods of governance. To get there (wherever that is) implies sweeping the current governance away. Oracle may not be prepared, but the OGB is brave enough to recognize that necessity and take the first steps. We would prefer to do so in concert with Oracle, hence the request that an official liaison be made available.
This move should also serve as a reality check and wake up call. Nobody - either within or outside Oracle - should have any excuses for being unaware of how bad things have become.
OpenSolaris stands at a crossroads. Many routes are open, there are choices available and decisions to be made. Simply standing still, wringing our hands and waiting indefinitely for Oracle to show up with a map, isn't an option. We need to break the shackles that tie us to this place and move forward.
So, and this hasn't been an easy decision, we have resolved:
The OGB is keen to promote the uptake and open development of OpenSolaris and to work on behalf of the community with Oracle, as such the OGB needs Oracle to appoint a liaison by August 16, 2010, who has the authority to talk about the future of OpenSolaris and its interaction with the OpenSolaris community. Otherwise the OGB will take action at the August 23 meeting to trigger the clause in the OGB charter that will return control of the community to Oracle.
Now, and sorry Ben, this isn't a "start talking to us or we'll just shot ourselves in the head" ultimatum. We're already on life support, if there are no signs of life then life support will be turned off.
Continuing on, or waiting indefinitely, merely perpetuates a lie. All is not well, and we would all be foolish to believe that it is. To do so would simply be delusional.
It may be nice for some to think that Oracle will ride up on a white charger to save the day. Even if that were to happen, it wouldn't really change the reality of the situation: that the current state of the community is essentially incompatible with the OpenSolaris charter and constitution, and that we need to move forward to a new organization that has new methods of governance. To get there (wherever that is) implies sweeping the current governance away. Oracle may not be prepared, but the OGB is brave enough to recognize that necessity and take the first steps. We would prefer to do so in concert with Oracle, hence the request that an official liaison be made available.
This move should also serve as a reality check and wake up call. Nobody - either within or outside Oracle - should have any excuses for being unaware of how bad things have become.
OpenSolaris stands at a crossroads. Many routes are open, there are choices available and decisions to be made. Simply standing still, wringing our hands and waiting indefinitely for Oracle to show up with a map, isn't an option. We need to break the shackles that tie us to this place and move forward.
Thursday, June 24, 2010
Wednesday, June 02, 2010
Up, up, and away
It was my birthday recently (and boy do I feel old). It's increasingly difficult to think of decent gifts I can ask for, so I've started to ask for things to do rather than things to keep. So this year Mel bought me a flight from the Imperial War Museum at Duxford, courtesy of Classic Wings.

This was in a 70 year old Dragon Rapide (above). We arrived nice and early, but the weather wasn't clearing as forecast (does it ever?) so we delayed for a while for the cloud to lift and had a look round the museum.
Then we (8 of us in all) clambered in, belted up, and set off. Two immediate impressions: for one thing, the seats are very comfortable and the legroom very decent, so much better than a modern airliner in that respect; for another, the thing is loud - you can't hold a conversation, and I imagine that several hours would become quite painful.

We were just below the clouds (a couple of times we drifted into the cloud briefly) but the view was spectacular. We flew north, round Cambridge (above) then up to Ely, did a circle, then down to Newmarket and back to Duxford (below).

Thanks Mel! I hugely enjoyed the experience.

This was in a 70 year old Dragon Rapide (above). We arrived nice and early, but the weather wasn't clearing as forecast (does it ever?) so we delayed for a while for the cloud to lift and had a look round the museum.
Then we (8 of us in all) clambered in, belted up, and set off. Two immediate impressions: for one thing, the seats are very comfortable and the legroom very decent, so much better than a modern airliner in that respect; for another, the thing is loud - you can't hold a conversation, and I imagine that several hours would become quite painful.

We were just below the clouds (a couple of times we drifted into the cloud briefly) but the view was spectacular. We flew north, round Cambridge (above) then up to Ely, did a circle, then down to Newmarket and back to Duxford (below).

Thanks Mel! I hugely enjoyed the experience.
Sunday, May 23, 2010
KAR 0.2
I've just released an updated version of KAR, the kstat activity reporter, and a matching JKstat update.
This version carries on with the original aim of simply saving all the kstats and processing them at point of use, rather than trying to predict which output might be useful at the start.
Originally, I was using kstat -p output, and I've had to move on from that. There were a couple of minor issues with the kstat -p output that I ended up having to fix. The major one was that the times from IO kstats were converted from nanoseconds into floating-point seconds. I had a quick look to see if I could supply a modified kstat, but the conversion takes place deep inside perl - it's not just a simple presentation tweak. I could have written special-case parsing code, but it's easier and more reliable to simple generate the correct data in the first place. (Simply printing kstats is pretty trivial to code, so I did.) Having fixed that, I made a couple of other minor changes to make the output more complete (including the kstat type) and smaller and quicker to parse (eliminating all duplicates of the name of the kstat).
The overhead of running kar is reduced. The storage requirement is halved from the first version, and the cpu for a data collection is cut from over 0.2s to about 0.01s on my machine. Which is all good - you want to minimise the perturbation on the system caused by any monitoring.
I added a little sar output emulator. Just to prove that I could, printing out the cpu utilization like the default sar output. The more interesting one was to generate iostat output, which is what led me to create a custom data collector. Of course, now that I have a complete set of kstats to munge, most of the stat tools in Solaris could be replicated to show what they would have looked like over time (albeit at fairly low time resolution). And, once the CLI tools are exhausted, generation of graphs is next on the list.
This version carries on with the original aim of simply saving all the kstats and processing them at point of use, rather than trying to predict which output might be useful at the start.
Originally, I was using kstat -p output, and I've had to move on from that. There were a couple of minor issues with the kstat -p output that I ended up having to fix. The major one was that the times from IO kstats were converted from nanoseconds into floating-point seconds. I had a quick look to see if I could supply a modified kstat, but the conversion takes place deep inside perl - it's not just a simple presentation tweak. I could have written special-case parsing code, but it's easier and more reliable to simple generate the correct data in the first place. (Simply printing kstats is pretty trivial to code, so I did.) Having fixed that, I made a couple of other minor changes to make the output more complete (including the kstat type) and smaller and quicker to parse (eliminating all duplicates of the name of the kstat).
The overhead of running kar is reduced. The storage requirement is halved from the first version, and the cpu for a data collection is cut from over 0.2s to about 0.01s on my machine. Which is all good - you want to minimise the perturbation on the system caused by any monitoring.
I added a little sar output emulator. Just to prove that I could, printing out the cpu utilization like the default sar output. The more interesting one was to generate iostat output, which is what led me to create a custom data collector. Of course, now that I have a complete set of kstats to munge, most of the stat tools in Solaris could be replicated to show what they would have looked like over time (albeit at fairly low time resolution). And, once the CLI tools are exhausted, generation of graphs is next on the list.
Saturday, May 22, 2010
RHCE
This last week I've been away on a training course, the Red Hat RHCE rapid track course. It's been a long time since I did formal training (anything beyond the odd hour or so, at least), so I wasn't sure how it was going to go.
All in all a success, I think. I certainly learnt a lot, and passed the exam.
As anyone who has done the RHCE exam knows, I can't really talk about any of the details. But I think the following would be helpful to others like myself:
Red Hat do a transition course for Solaris Administrators. I thought about that, and skipped it. I had no problem adjusting to RHEL, so I'm not sure what value the course for Solaris admins would be - I would have thought that if you're a bit unsure, then doing the full RHCE course rather that the Solaris course with the fast-track would be a better bet.
All in all a success, I think. I certainly learnt a lot, and passed the exam.
As anyone who has done the RHCE exam knows, I can't really talk about any of the details. But I think the following would be helpful to others like myself:
- If you're experienced in unix systems administration, and are used to administering applications, you should cope. Easily.
- With experience on other platforms, the rapid-track course is very useful.
- The RHCE exam covers a lot of application ground. For me, it was really a case of learning how Red Hat has its own tweaks (and how things like the firewall and SELinux interact with applications).
- I found that going away for the course was really helpful. It allowed me to focus on the course without distractions.
Red Hat do a transition course for Solaris Administrators. I thought about that, and skipped it. I had no problem adjusting to RHEL, so I'm not sure what value the course for Solaris admins would be - I would have thought that if you're a bit unsure, then doing the full RHCE course rather that the Solaris course with the fast-track would be a better bet.
Sunday, May 09, 2010
JKstat 0.37
So JKstat now reaches version 0.37, with the usual spread of minor fixes, enhancements, and new features.
One enhancement is the extension to 64-bit. For JKstat itself, there's no need to run it in 64-bit mode, but I need 64-bit libraries to allow JKstat to run inside a 64-bit JVM. One example of this would be SolView, which would have to run in 64-bit mode to show the sizes of 64-bit processes using JProc.
A new feature is the ability to generate png images directly from the cli, using input such as the
One of the minor fixes this time is to support the recent 1.3 release of JavaFX . It looks like JavaFX isn't binary compatible between releases, so code needs to be rebuilt to match whichever version you're using, which is a shame. Also, this version optimized away some of my method calls and I needed to fool it into not doing so.
One enhancement is the extension to 64-bit. For JKstat itself, there's no need to run it in 64-bit mode, but I need 64-bit libraries to allow JKstat to run inside a 64-bit JVM. One example of this would be SolView, which would have to run in 64-bit mode to show the sizes of 64-bit processes using JProc.
A new feature is the ability to generate png images directly from the cli, using input such as the
kstat -p archives used by kar.One of the minor fixes this time is to support the recent 1.3 release of JavaFX . It looks like JavaFX isn't binary compatible between releases, so code needs to be rebuilt to match whichever version you're using, which is a shame. Also, this version optimized away some of my method calls and I needed to fool it into not doing so.
Wednesday, May 05, 2010
Solaris Process data from Java
I've got a java interface, called jproc to process data in Solaris, using the procfs filesystem.
In the latest version, apart from starting on a tree-view (currently known to be buggy and woefully incomplete), there are a couple of little technical tricks I had to learn.
The first is that accessing the process data, particularly sizes, of a 64-bit application, requires a 64-bit application. That's why tools such as top, ps, and prstat are 64-bit (via isaexec). Now, there's a 64-bit java for Solaris, so I needed to compile my JNI library in 64-bit mode too. Normally you just call
The other thing I wanted to do was to make the display of items in tables a little more readable. JTable just picks up the type of data and defaults to a fairly basic display. My first attempt was to convert my data to pretty strings, and display those, but that had a couple of snags: by default strings get left-justified, which wasn't what I wanted, and sorting broke because it sorted the strings rather than the underlying numerical data.
The answer, of course, is to use a custom TableCellRenderer. This only affects the presentation, so that sorting works correctly against the underlying data. So far all I've done is simply humanize some of the values, but so much more is possible.
In the latest version, apart from starting on a tree-view (currently known to be buggy and woefully incomplete), there are a couple of little technical tricks I had to learn.
The first is that accessing the process data, particularly sizes, of a 64-bit application, requires a 64-bit application. That's why tools such as top, ps, and prstat are 64-bit (via isaexec). Now, there's a 64-bit java for Solaris, so I needed to compile my JNI library in 64-bit mode too. Normally you just call
but for 64-bit mode it's a little more complicated than that. In particular, just adding
cc -G
-m64 the way you would expect doesn't work. And it's different on x86 and sparc. So what I've found works, is:
amd64:
cc -Kpic -shared -m64
sparc:
cc -xcode=pic13 -shared -m64
The other thing I wanted to do was to make the display of items in tables a little more readable. JTable just picks up the type of data and defaults to a fairly basic display. My first attempt was to convert my data to pretty strings, and display those, but that had a couple of snags: by default strings get left-justified, which wasn't what I wanted, and sorting broke because it sorted the strings rather than the underlying numerical data.
The answer, of course, is to use a custom TableCellRenderer. This only affects the presentation, so that sorting works correctly against the underlying data. So far all I've done is simply humanize some of the values, but so much more is possible.
Sunday, March 14, 2010
Beyond sar
The old standby for recording historical system activity is sar - system activity reporter. There are many alternatives, both free and commercial, but sar has the advantage that it comes with the OS, and pretty much any version of any (unix-like) OS.
Because it's there, we use sar, saving it's output into a big archive and using tools like sar2rrd to produce charts. (It's not the only thing we use, of course.)
The problem is that, particularly on Solaris, sar is terrible. The data it collects is woefully incomplete - network data is the worst, being completely absent, but there's much more missing. Some of what is present is aggregated away so that much of the details is lost. And the list of what's present is fixed, so the whole framework is completely non-extensible.
So, I'm fed up with that, and need to do better. Note that most tools out there don't help with capturing all the data, as they have their own preconceived notions of what data might be useful (although they are generally far more complete than sar).
Enter kar - the kstat activity reporter. This is really amazingly simple. Given that (almost) all the performance data you want is obtained from kstats, simply save all the kstats on a regular basis. The implementation I have here is to save
I've said it a couple of times above, but I'm going to say it again: the key advantage here is that the data is complete and thereby naturally extensible. I don't want to enhance sar by trying to cherry-pick interesting statistics (and we could all argue for months about what might go on the list). By saving everything you automatically pick up anything new that's added. And you let consumers decide which of the statistics are interesting when you get to the post-processing phase. Say I wanted to look at the historical behaviour of the zfs ARC - no problem, it's all there in the kstats.
Using
If that wasn't enough, jkstat 0.35 has support for reading in the output of kar in both the browser and chart builder.
or
will do the trick.
Because it's there, we use sar, saving it's output into a big archive and using tools like sar2rrd to produce charts. (It's not the only thing we use, of course.)
The problem is that, particularly on Solaris, sar is terrible. The data it collects is woefully incomplete - network data is the worst, being completely absent, but there's much more missing. Some of what is present is aggregated away so that much of the details is lost. And the list of what's present is fixed, so the whole framework is completely non-extensible.
So, I'm fed up with that, and need to do better. Note that most tools out there don't help with capturing all the data, as they have their own preconceived notions of what data might be useful (although they are generally far more complete than sar).
Enter kar - the kstat activity reporter. This is really amazingly simple. Given that (almost) all the performance data you want is obtained from kstats, simply save all the kstats on a regular basis. The implementation I have here is to save
kstat -p output into files inside zip archives. Now, that's not ideal, but it has some advantages: it's almost zero effort, it gives complete coverage, and it's naturally extensible. If it works out and is found to be useful, more optimal mechanisms could be defined.I've said it a couple of times above, but I'm going to say it again: the key advantage here is that the data is complete and thereby naturally extensible. I don't want to enhance sar by trying to cherry-pick interesting statistics (and we could all argue for months about what might go on the list). By saving everything you automatically pick up anything new that's added. And you let consumers decide which of the statistics are interesting when you get to the post-processing phase. Say I wanted to look at the historical behaviour of the zfs ARC - no problem, it's all there in the kstats.
Using
kstat -p is a convenient shortcut, but does have other advantages. Because the output is textual, all your favourite analysis tools - awk, sed, perl, grep, python, whatever - can munge the data with no effort. And you can chuck the data into your graphing application of choice.If that wasn't enough, jkstat 0.35 has support for reading in the output of kar in both the browser and chart builder.
./jkstat browser -z /var/adm/ka/ka-2010-03-01.zip
or
./jkstat chartbuilder -z /var/adm/ka/ka-2010-03-01.zip
will do the trick.
Friday, March 05, 2010
JKstat 0.34
I've just pushed out a minor update to JKstat.
The change here (apart from a couple of minor bugfixes and a jnetloadfx example to remind me what JavaFX looked like) is the addition of a class to update multiple accessories together. Previously, in demos such as iostat and cpustate, each item had its own timer loop and was responsible for handling its own updates. This was especially apparent in the kmemalloc example in SolView - it was obvious that separate widgets weren't being updated simultaneously.
Now I can just have a single update loop that updates multiple accessories. Not only does it look neater, but there are noticeable improvements in memory and cpu usage from only having one timer instead of many.
Coming up next is more related work. The ability to read historical
The change here (apart from a couple of minor bugfixes and a jnetloadfx example to remind me what JavaFX looked like) is the addition of a class to update multiple accessories together. Previously, in demos such as iostat and cpustate, each item had its own timer loop and was responsible for handling its own updates. This was especially apparent in the kmemalloc example in SolView - it was obvious that separate widgets weren't being updated simultaneously.
Now I can just have a single update loop that updates multiple accessories. Not only does it look neater, but there are noticeable improvements in memory and cpu usage from only having one timer instead of many.
Coming up next is more related work. The ability to read historical
kstat -p output works fine, but requires some changes so that you step through the data rather than continuously updating in time. (If you think about it for a moment, the class I mentioned above is one example of updating the time and then telling the world to update, so it's - albeit only tangentially - related.) These changes are likely to be a bit complex, so I also decided to cut a version before starting to make more significant changes to the code.
Friday, February 26, 2010
Opening up some details of OpenSolaris under Oracle
The OpenSolaris Annual Meeting is under way on IRC. (The meeting itself is one of those odd side-effects of the old constitution, it's never really been used as a proper meeting.)
We were fortunate enough today to have Dan Roberts along to answer questions. A log of the session is available - for the conversation with DanR look just after the noon mark.
Positive, simple and straightforward:
And:
In terms of investment:
Questioned on open development:
with the caveat:
(Although the model that came to my mind was the fishworks/analytics add-ons that go into the open storage systems. So that's not a change.)
In reply to a question "for 'regular' users and contributor to Open Solaris - do you figure that anything will change in terms of how open solaris is delivered and how developers contribute?":
On the subject of User Groups, there's already been some outreach (as I've noted before). Part of the story here is that Oracle have a group for community support, so that group will take over the support that has come from Sun in the past. User groups still look after themselves, but wil be centrally supported (if they want and need it) through the new route. I also expect some user groups to form relationships with other organisations such as the independent Oracle User Groups, and all user groups will be free to take whatever steps they wish to in that area.
Support is an area that has been contentious recently. On this:
(Read it this way: if anybody wanted support, they should have paid up. I've heard what "very little sales" means. My one concern in this area is support for Solaris/OpenSolaris on 3rd-party systems.)
All in all, though, thanks to Dan for sticking his head above the parapet. And - while there are clearly devils in the details - it's clear than Oracle plan to keep pushing OpenSolaris forward, so rumours of its death have been greatly exaggerated.
We were fortunate enough today to have Dan Roberts along to answer questions. A log of the session is available - for the conversation with DanR look just after the noon mark.
Positive, simple and straightforward:
Oracle will continue to make OpenSolaris available as open source, and Oracle will continue to actively support and participate in the community
And:
Oracle will also continue to deliver OpenSolaris releases, including the upcoming OpenSolaris 2010.03 release.
In terms of investment:
Oracle is investing more in Solaris than Sun did prior to the acquisition, and will continue to contribute technologies to OpenSolaris, as Oracle already does for many other open source projects
Questioned on open development:
Oracle will continue to develop technologies in the open, as we do today
with the caveat:
There may be some things we choose not to open source going forward, similar to how MySQL manages certain value add at the top of the stack.
(Although the model that came to my mind was the fishworks/analytics add-ons that go into the open storage systems. So that's not a change.)
In reply to a question "for 'regular' users and contributor to Open Solaris - do you figure that anything will change in terms of how open solaris is delivered and how developers contribute?":
Love to see the tech journal crowd participating! And yes, regular users will find things mostly unchanged. Contributors also.
On the subject of User Groups, there's already been some outreach (as I've noted before). Part of the story here is that Oracle have a group for community support, so that group will take over the support that has come from Sun in the past. User groups still look after themselves, but wil be centrally supported (if they want and need it) through the new route. I also expect some user groups to form relationships with other organisations such as the independent Oracle User Groups, and all user groups will be free to take whatever steps they wish to in that area.
Support is an area that has been contentious recently. On this:
And Oracle will ensure customers running OpenSolaris have an option for support on Oracle Sun Systems where it's required, though given the very little sales here this will not be something we expect many customers to deploy going forward. Solaris is our focus, on both SPARC and x86.
(Read it this way: if anybody wanted support, they should have paid up. I've heard what "very little sales" means. My one concern in this area is support for Solaris/OpenSolaris on 3rd-party systems.)
All in all, though, thanks to Dan for sticking his head above the parapet. And - while there are clearly devils in the details - it's clear than Oracle plan to keep pushing OpenSolaris forward, so rumours of its death have been greatly exaggerated.
Friday, February 19, 2010
Nominations for the 2010-2011 OGB now open
The OpenSolaris Governing Board is now accepting nominations for candidates to run for the OGB term starting April 2010. Anyone registered with an account on the OpenSolaris.org website is eligible to be nominated, even if not currently recognized as a Core Contributor or Contributor to any existing community group.
Nominations should be e-mailed to ogb-discuss@opensolaris.org (please make sure you either use the web forum or subscribe to the mailing list first to avoid getting caught in the spam-filter/moderation queue - use the forums or sign up at http://mail.opensolaris.org/mailman/listinfo/ogb-discuss)
Nominations must submitted by a current Core Contributor - those who are interested in running may nominate themselves if they are a Core Contributor already (see the current lists of Core Contributors on https://auth.opensolaris.org), or send mail to the mailing list asking for a Core Contributor to formally nominate them if they are not a Core Contributor.
Those who are nominated by others must send mail to ogb-discuss accepting their nomination.
All candidates will be required to submit a statement before the election containing "a list of their commercial affiliation, or other interests related to OpenSolaris, so that a voting member can understand the context from which they would act on the OGB and the likely biases they would bring."
The deadline for submitting and accepting nominations will be 23:59 in the US/Pacific timezone on Monday, March 1. Statements from nominees are due before the start of voting, which is scheduled to begin at 00:00 on Monday, March 8.
Nominations and acceptances will be tracked during the nomination period using the OpenSolaris bugzilla at http://defect.opensolaris.org/ in the "ogb" product under the "nominations" category.
More information about the OpenSolaris elections and governance can be found at:
Nominations should be e-mailed to ogb-discuss@opensolaris.org (please make sure you either use the web forum or subscribe to the mailing list first to avoid getting caught in the spam-filter/moderation queue - use the forums or sign up at http://mail.opensolaris.org/mailman/listinfo/ogb-discuss)
Nominations must submitted by a current Core Contributor - those who are interested in running may nominate themselves if they are a Core Contributor already (see the current lists of Core Contributors on https://auth.opensolaris.org), or send mail to the mailing list asking for a Core Contributor to formally nominate them if they are not a Core Contributor.
Those who are nominated by others must send mail to ogb-discuss accepting their nomination.
All candidates will be required to submit a statement before the election containing "a list of their commercial affiliation, or other interests related to OpenSolaris, so that a voting member can understand the context from which they would act on the OGB and the likely biases they would bring."
The deadline for submitting and accepting nominations will be 23:59 in the US/Pacific timezone on Monday, March 1. Statements from nominees are due before the start of voting, which is scheduled to begin at 00:00 on Monday, March 8.
Nominations and acceptances will be tracked during the nomination period using the OpenSolaris bugzilla at http://defect.opensolaris.org/ in the "ogb" product under the "nominations" category.
More information about the OpenSolaris elections and governance can be found at:
Tuesday, February 16, 2010
OpenSolaris: Oracle, where art thou?
After a prolonged wait, Oracle have now completed their takeover of Sun. Late January, they presented their plans for taking Sun's products forward.
OpenSolaris wasn't even mentioned.If you look carefully, it's on a slide, but that's about it.
That silence has continued. OpenSolaris has - publicly at least - been completely ignored by Oracle. It's as if we don't exist.
Somewhat perturbed by this state of affairs, I asked for a communication channel to be established between Oracle and the OGB. This was ignored. The OGB pointed out (in pretty strong terms) to those Sun staff that we do have communication with that some level of contact was needed. We haven't heard back.
It's not as if we're asking for much; the very basic start of a conversation. I've no doubt that Oracle are very busy, but not even bothering to say hello?
Recently, Oracle sent a welcome letter to (some of) the OpenSolaris User Group leaders. While any contact is welcome, the manner in which it was done was unfortunate. It ignored OpenSolaris as a whole, ignored all the other groups that make up the OpenSolaris community, and completely bypassed the Governing Board. This is shockingly poor treatment.
I've attempted to make contact. Again, this approach has been completely ignored. I have not even been accorded the common courtesy of an acknowledgment.
I'm not the only one. It's clear that the OpenSolaris community are very concerned, and they're being left completely in the dark. Ben blogged an Open Letter to Oracle and that doesn't seem to have elicited any response either.
At a most basic level, this is simply impolite. Even downright rude. Is it a sign of something more sinister? Well, nothing at all has been said that would allow anyone ta make a judgment, but it's fuelling the FUD machine.
Needless to say, this is pretty inauspicious start to a relationship. It's about time for Oracle to stop avoiding us and make their intentions known, especially with the OpenSolaris Governing Board Elections just round the corner.
OpenSolaris wasn't even mentioned.If you look carefully, it's on a slide, but that's about it.
That silence has continued. OpenSolaris has - publicly at least - been completely ignored by Oracle. It's as if we don't exist.
Somewhat perturbed by this state of affairs, I asked for a communication channel to be established between Oracle and the OGB. This was ignored. The OGB pointed out (in pretty strong terms) to those Sun staff that we do have communication with that some level of contact was needed. We haven't heard back.
It's not as if we're asking for much; the very basic start of a conversation. I've no doubt that Oracle are very busy, but not even bothering to say hello?
Recently, Oracle sent a welcome letter to (some of) the OpenSolaris User Group leaders. While any contact is welcome, the manner in which it was done was unfortunate. It ignored OpenSolaris as a whole, ignored all the other groups that make up the OpenSolaris community, and completely bypassed the Governing Board. This is shockingly poor treatment.
I've attempted to make contact. Again, this approach has been completely ignored. I have not even been accorded the common courtesy of an acknowledgment.
I'm not the only one. It's clear that the OpenSolaris community are very concerned, and they're being left completely in the dark. Ben blogged an Open Letter to Oracle and that doesn't seem to have elicited any response either.
At a most basic level, this is simply impolite. Even downright rude. Is it a sign of something more sinister? Well, nothing at all has been said that would allow anyone ta make a judgment, but it's fuelling the FUD machine.
Needless to say, this is pretty inauspicious start to a relationship. It's about time for Oracle to stop avoiding us and make their intentions known, especially with the OpenSolaris Governing Board Elections just round the corner.
Sunday, February 14, 2010
OpenSolaris Community Reports 2009-2010
With the end of this year's OGB term coming up, I just sent out the following request for reports to various mailing lists. Historically, we've not been very good at reporting what we're doing in the OpenSolaris community, and really need to do better.
There is a lot of work taking place in the OpenSolaris community. In order to inform the OGB, the rest of the community, and those outside our community of all the work that's being done, the OGB seeks to collect reports from the communities, projects, and user groups that make up our community.
For the 2009-2010 period, we seek brief (presentation style, one-page would be ideal but don't force it if this doesn't fit) reports from all community groups, projects, and user groups, highlighting their achievements. We aim to combine them into a single presentation that could be used by others. If there is additional material - video or images, or full presentations, we would like to know about that too.
Some templates you may wish to use are available at:
http://hub.opensolaris.org/bin/view/Community+Group+ogb/Reports
Some suggested details that could be included:
Communities: projects that have been newly sponsored or completed, and events or meetings that have occurred
Projects: aims, new features, build number if the project has integrated
User Groups: number of attendees, frequency of meetings, involvement with other groups or events
Please reply directly to me by email.
There is a lot of work taking place in the OpenSolaris community. In order to inform the OGB, the rest of the community, and those outside our community of all the work that's being done, the OGB seeks to collect reports from the communities, projects, and user groups that make up our community.
For the 2009-2010 period, we seek brief (presentation style, one-page would be ideal but don't force it if this doesn't fit) reports from all community groups, projects, and user groups, highlighting their achievements. We aim to combine them into a single presentation that could be used by others. If there is additional material - video or images, or full presentations, we would like to know about that too.
Some templates you may wish to use are available at:
http://hub.opensolaris.org/bin/view/Community+Group+ogb/Reports
Some suggested details that could be included:
Communities: projects that have been newly sponsored or completed, and events or meetings that have occurred
Projects: aims, new features, build number if the project has integrated
User Groups: number of attendees, frequency of meetings, involvement with other groups or events
Please reply directly to me by email.
Sunday, January 31, 2010
A better terminal, part 2
Thanks for the comments on my search for a better terminal.
First. Eterm. So if I build it with gcc, it SEGVs on me, and it won't compile with Studio 12. I used to use it, but don't seem to have a working version available right now.
As for providing a binary for evilvte, I'm not sure how useful that is. The only way to configure it is to build from source. And I'm pretty sure my configuration choices are likely to be different from anyone else's.
On to terminator. (Which one? This one, or that one?) The first one fails to build for me - not only does it require a non-standard make, it requires a particular version of that non-standard make, and one my regular Solaris 10 box doesn't have. The second one just gives a python traceback.
Then there's the whole rxvt family. I actually use rxvt quite a bit, when I want to run something (like top) in a throwaway terminal window, due to how lightweight it is. But it has to be said that it's nowhere near as lightweight as it was, and urxvt is much heavier than xterm. There are little irritants too, such urxvt needs its own terminfo entry adding, which is just another barrier. Or not being able to override rxvt's uses of a stipple pattern in the xterm-style scrollbar (I always make it solid).
I've tried quite a few others, most of which plain don't build.
First. Eterm. So if I build it with gcc, it SEGVs on me, and it won't compile with Studio 12. I used to use it, but don't seem to have a working version available right now.
As for providing a binary for evilvte, I'm not sure how useful that is. The only way to configure it is to build from source. And I'm pretty sure my configuration choices are likely to be different from anyone else's.
On to terminator. (Which one? This one, or that one?) The first one fails to build for me - not only does it require a non-standard make, it requires a particular version of that non-standard make, and one my regular Solaris 10 box doesn't have. The second one just gives a python traceback.
Then there's the whole rxvt family. I actually use rxvt quite a bit, when I want to run something (like top) in a throwaway terminal window, due to how lightweight it is. But it has to be said that it's nowhere near as lightweight as it was, and urxvt is much heavier than xterm. There are little irritants too, such urxvt needs its own terminfo entry adding, which is just another barrier. Or not being able to override rxvt's uses of a stipple pattern in the xterm-style scrollbar (I always make it solid).
I've tried quite a few others, most of which plain don't build.
Saturday, January 30, 2010
Looking for a better terminal
It sometimes seems I spend most of my life in xterm, usually logged into a remote server.
And while xterm isn't bad, as terminal emulators go, sometimes I want a bit more jazz and reliability. Recently xterm hasn't been as reliable as it should be, and it also doesn't cut it for some use cases - logged into a Sun (oops, Oracle...) ILOM, for instance. Things like color, background images, transparency, all break up the monotony,
Locally on my work desktop I run gnome-terminal for some stuff - it's heavy resource consumption is offset by the fact that I'm running a lot of windows. But it doesn't work half as well on remote servers or under other graphical environments. And gnome-terminal is a resource hog.
At home I run Xfce, and the Terminal is just as functional as gnome-terminal but with only half the resource requirements. One showstopper (and this is a real killer for a large number of otherwise decent applications) is its requirement for D-Bus, which makes it far too difficult to run standalone in an arbitrary environment.
So I've been looking at some alternatives, and quite like evilvte. It's functionally equivalent to gnome-terminal and the Xfce Terminal, using the same vte widget, but even lighter weight and faster and with much reduced dependencies. (In particular, no D-Bus.) So it could be used as a replacement for xterm.
Building it is somewhat manual. (But no stupid build system to fight with.) And configuration is a case of editing config.h and running make again to rebuild the binary. But I like it.
And while xterm isn't bad, as terminal emulators go, sometimes I want a bit more jazz and reliability. Recently xterm hasn't been as reliable as it should be, and it also doesn't cut it for some use cases - logged into a Sun (oops, Oracle...) ILOM, for instance. Things like color, background images, transparency, all break up the monotony,
Locally on my work desktop I run gnome-terminal for some stuff - it's heavy resource consumption is offset by the fact that I'm running a lot of windows. But it doesn't work half as well on remote servers or under other graphical environments. And gnome-terminal is a resource hog.
At home I run Xfce, and the Terminal is just as functional as gnome-terminal but with only half the resource requirements. One showstopper (and this is a real killer for a large number of otherwise decent applications) is its requirement for D-Bus, which makes it far too difficult to run standalone in an arbitrary environment.
So I've been looking at some alternatives, and quite like evilvte. It's functionally equivalent to gnome-terminal and the Xfce Terminal, using the same vte widget, but even lighter weight and faster and with much reduced dependencies. (In particular, no D-Bus.) So it could be used as a replacement for xterm.
Building it is somewhat manual. (But no stupid build system to fight with.) And configuration is a case of editing config.h and running make again to rebuild the binary. But I like it.
Friday, January 29, 2010
Stupid build systems
There was a time when building software was easy. You typed
In the advanced days of the 21st century, of course, such simplicity - something that actually works - is rarely to be found. We have things like the autotools (the evil behind ./configure) that basically involves making a bunch of unsubstantiated guesses about your system and constructing a random build configuration based on it. And heaven help you if libtool gets its teeth into your software - it's almost guaranteed to miscompile your software in a manner that's undebuggable and unfixable.
So cmake promised to be a welcome relief from this madness. Only it's not. I've been having a go at building the awesome window manager on Solaris. When it works I'll post more details, but I almost flipped when having fought it into submission and built it successfully, I did the install and saw:
And, on checking, it had done exactly that - stripped out the RPATH information so the binary it had carefully built stood no chance whatsoever of actually working.
And this is progress?
make and it almost always worked. Sometimes you had to know the secret incantation of xmkmf -a, but usually if make didn't work straight off the software wasn't worth using.In the advanced days of the 21st century, of course, such simplicity - something that actually works - is rarely to be found. We have things like the autotools (the evil behind ./configure) that basically involves making a bunch of unsubstantiated guesses about your system and constructing a random build configuration based on it. And heaven help you if libtool gets its teeth into your software - it's almost guaranteed to miscompile your software in a manner that's undebuggable and unfixable.
So cmake promised to be a welcome relief from this madness. Only it's not. I've been having a go at building the awesome window manager on Solaris. When it works I'll post more details, but I almost flipped when having fought it into submission and built it successfully, I did the install and saw:
-- Removed runtime path from "/packages/awesome/bin/awesome"
And, on checking, it had done exactly that - stripped out the RPATH information so the binary it had carefully built stood no chance whatsoever of actually working.
And this is progress?
Wednesday, January 27, 2010
Solaris Containers and Shared Memory
I've been migrating some old systems from truly antique Sun boxes onto a small number of new Sun T5240s. Lots of zones, one per new physical system.
This includes some truly antique versions of oracle.
In order to keep the version police happy with the compatibility matrix, they wanted Solaris 8. Despite the fact that it works fine with Solaris 10, they insisted on Solaris 8. Enter Solaris 8 Containers.
Now, Solaris 10 has reasonable default shared memory settings. However, the Solaris 8 Container gives a faithful emulation of a Solaris 8 system, including miserly shared memory settings. How to set better values, because the normal Solaris 10 games don't apply?
The solution is simple, so simple that it never actually occurred to me. Simply put the settings you want in the Container's /etc/system file in the traditional way, and reboot the Container.
This includes some truly antique versions of oracle.
In order to keep the version police happy with the compatibility matrix, they wanted Solaris 8. Despite the fact that it works fine with Solaris 10, they insisted on Solaris 8. Enter Solaris 8 Containers.
Now, Solaris 10 has reasonable default shared memory settings. However, the Solaris 8 Container gives a faithful emulation of a Solaris 8 system, including miserly shared memory settings. How to set better values, because the normal Solaris 10 games don't apply?
The solution is simple, so simple that it never actually occurred to me. Simply put the settings you want in the Container's /etc/system file in the traditional way, and reboot the Container.
Tuesday, January 26, 2010
Preconfiguring Containers with sysidcfg
You can preconfigure a Solaris Zone by placing a valid sysidcfg file into /etc/sysidcfg in the zone, so it finds all the information when it boots.
What's also true, at least for native zones on Solaris 10, is that you can specify a cut-down sysidcfg file. For example:
If you try doing this on a Solaris 8 Container, it will go interactive. So you need to supply a bit more information. Such as:
where I've added the netmask and protocol_ipv6 settings to the network_interface section, and told it a timeserver. Clearly the Solaris 10 zone can work these out for itself, but a Solaris 8 branded zone needs to be told explicitly. (Also, it doesn't need the nfs4_domain, as that makes no sense for a Solaris 8 system.)
What's also true, at least for native zones on Solaris 10, is that you can specify a cut-down sysidcfg file. For example:
network_interface=PRIMARY {
hostname=mars
}
system_locale=C
timezone=US/Pacific
name_service=NIS {
domain_name=foo.com
name_server=bar.foo.com(192.168.1.1)
}
security_policy=NONE
terminal=xterm
root_password=0123456789abcd
nfs4_domain=foo.com
If you try doing this on a Solaris 8 Container, it will go interactive. So you need to supply a bit more information. Such as:
network_interface=PRIMARY {
hostname=mars
netmask=255.255.255.0
protocol_ipv6=no
}
system_locale=C
timezone=US/Pacific
name_service=NIS {
domain_name=foo.com
name_server=bar.foo.com(192.168.1.1)
}
timeserver=localhost
security_policy=NONE
terminal=xterm
root_password=0123456789abcd
where I've added the netmask and protocol_ipv6 settings to the network_interface section, and told it a timeserver. Clearly the Solaris 10 zone can work these out for itself, but a Solaris 8 branded zone needs to be told explicitly. (Also, it doesn't need the nfs4_domain, as that makes no sense for a Solaris 8 system.)
Saturday, January 23, 2010
Compressing Backup Catalogs
Backup solutions such as NetBackup keep a catalog so that you can find a file that you need to get back. Clearly, with a fair amount of data being backed up, the catalog can become very large. I'm just sizing a replacement backup system, and catalog size (and the storage for it) is a significant part of the problem.
One way that NetBackup deals with this is to compress old catalogs. On my Solaris server it seems to use the old compress command, which gives you about 3-fold compression by the looks of it: 3.7G goes to 1.2G, for example.
However, there's a problem: in order to read an old catalog (in order to find something from an old backup) it has to be uncompressed. There's quite a delay while this happens, and even worse, you need disk space to handle the uncompressed catalog.
Playing about the other day, I wondered about using filesystem compression rather than application compression, with ZFS in mind. So, for that 3.7G sample:
Even with the ZFS default, we're doing almost as well. With gzip, we do much better. (And it's odd that gzip-9 does worse than gzip-1.)
However, even though the default level of compression doesn't compress the data quite as well as the application does, it's still much better to use ZFS to do the compression, as then you can compress all the data: if you leave it to the application then you always leave the recent data uncompressed for easy access, and only compress the old stuff. So assume a catalog twice the size above, and that we used NetBackup to compress half the catalog, then the disk used in the application case would be 3.7G uncompressed and 1.2G compressed. The total disk usage comes out as:
The conclusion is pretty clear: forget about getting NetBackup to compress its catalog, and get ZFS (or any other compressing filesystem) to do the job instead.
One way that NetBackup deals with this is to compress old catalogs. On my Solaris server it seems to use the old compress command, which gives you about 3-fold compression by the looks of it: 3.7G goes to 1.2G, for example.
However, there's a problem: in order to read an old catalog (in order to find something from an old backup) it has to be uncompressed. There's quite a delay while this happens, and even worse, you need disk space to handle the uncompressed catalog.
Playing about the other day, I wondered about using filesystem compression rather than application compression, with ZFS in mind. So, for that 3.7G sample:
| Compression | Size |
|---|---|
| Application | 1.2G |
| ZFS default | 1.4G |
| ZFS gzip-1 | 920M |
| ZFS gzip-9 | 939M |
Even with the ZFS default, we're doing almost as well. With gzip, we do much better. (And it's odd that gzip-9 does worse than gzip-1.)
However, even though the default level of compression doesn't compress the data quite as well as the application does, it's still much better to use ZFS to do the compression, as then you can compress all the data: if you leave it to the application then you always leave the recent data uncompressed for easy access, and only compress the old stuff. So assume a catalog twice the size above, and that we used NetBackup to compress half the catalog, then the disk used in the application case would be 3.7G uncompressed and 1.2G compressed. The total disk usage comes out as:
| Compression | Size |
|---|---|
| Application | 4.9G |
| ZFS default | 2.8G |
| ZFS gzip-1 | 1.8G |
| ZFS gzip-9 | 1.8G |
The conclusion is pretty clear: forget about getting NetBackup to compress its catalog, and get ZFS (or any other compressing filesystem) to do the job instead.
Subscribe to:
Posts (Atom)