We all know that just because something is new doesn't mean that it's better than what's gone before. A couple of examples I've had the misfortune to experience first-hand recently emphasize this:
Firefox 3 is dramatically inferior to Firefox 2. Not only does it feel much more sluggish, but the URL bar (in particular the drop-down menu) is terrible. Yes, the oldbar extension removes some of the maddening irritations of the look and feel, but the list of URLs presented is completely broken, to the point where it's worse than useless. I've not upgraded every machine I have, and the overall experience on the machines I have upgraded is pretty poor - so much so that I'm tempted to revert.
I've used emacs for decades. (And EDT/EVE/TPU before that.) For many years I've stayed with emacs 19.34, because it worked. Recently I've switched to emacs 22, because it's newer, maintained, and is what tends to be found on other systems. Again, the experience is staggeringly poor. Not only is it much slower but some of its features are just plain stupid. One of the more idiotic features I came across recently was that it assumes that a file named with a "zone" extension must be a DNS zone. (As a Solaris sysadmin, a zone is likely to be something else.) And if the file doesn't parse as it thinks a DNS zone file should then you are completely unable to even save the file - it's so smugly superior.
The world is full of other examples. Why do we put up with it?
Sunday, March 22, 2009
Saturday, March 21, 2009
Agile SysAdmin
A while back we had a talk at LOSUG about Agile System Administration. While presenting a particular view, I think Gordon was also trying to get us systems administrators to think more about the theory underlying the work that we do.
Development has formal techniques - Agile, XP, Scrum, pair programming, test-first. And note that these are at a different layer from the actual programming skills required to write the software.
Does Systems Administration have the same sorts of practices? Does it need them? Do the concepts of Agile Development translate into Systems Administration?
Gordon has a blog discussing some of his thoughts on the subject. I encourage those of you interested in the subject to read and contribute. (The home page of the blog is just the welcome; you'll need to look at the Archives and Categories to find the actual blog entries.)
For what it's worth, I think somewhat differently, preferring flexible and lightweight (preferably zero-touch) minimalist administration over mandated standardization and heavyweight processes.
Development has formal techniques - Agile, XP, Scrum, pair programming, test-first. And note that these are at a different layer from the actual programming skills required to write the software.
Does Systems Administration have the same sorts of practices? Does it need them? Do the concepts of Agile Development translate into Systems Administration?
Gordon has a blog discussing some of his thoughts on the subject. I encourage those of you interested in the subject to read and contribute. (The home page of the blog is just the welcome; you'll need to look at the Archives and Categories to find the actual blog entries.)
For what it's worth, I think somewhat differently, preferring flexible and lightweight (preferably zero-touch) minimalist administration over mandated standardization and heavyweight processes.
Sunday, March 08, 2009
SNMP GUI - Jangle 0.03
A little bit more work (thanks to all for comments and encouragement!) and a new version of Jangle is available.
Some highlights:
Enjoy!
Some highlights:
- Prototype tree view
- User-defined MIB location (from the File menu)
- Some error handling
- Work done in the background for faster startup and better responsiveness
- The graph has the human-readable name if we can rather than the numeric OID
Enjoy!
Monday, March 02, 2009
Jangle
One of the comments I got yesterday was that my new Java SNMP browser didn't work on Ubuntu. That wasn't entirely a surprise - with such a rough first cut I was astonished that it worked at all, even for me.
But anyway, that was easy enough to fix and I've released a new version that does run on Ubuntu (verified under 8.10) and that ought to me more sane and portable generally. One thing I need to work out is where the MIB files tend to be found on different systems.
I've renamed it to Jangle. It's possible to think of this as
Java Assistant for Networked Graphs that's, Like, Easy
but I wouldn't want you to read too much into it. Really.
Download, and run
(The new name has more zip, is less generic, and less likely to conflict with other tools.)
But anyway, that was easy enough to fix and I've released a new version that does run on Ubuntu (verified under 8.10) and that ought to me more sane and portable generally. One thing I need to work out is where the MIB files tend to be found on different systems.
I've renamed it to Jangle. It's possible to think of this as
Java Assistant for Networked Graphs that's, Like, Easy
but I wouldn't want you to read too much into it. Really.
Download, and run
./jangle browser(The new name has more zip, is less generic, and less likely to conflict with other tools.)
Sunday, March 01, 2009
A Java SNMP client
I've been looking at SNMP a bit more closely recently. One thing that has struck me is that while there are a number of java based SNMP clients, none of them seemed to be complete, and I couldn't obviously find one that could produce charts easily.
This is easy, right. So a little while later snmpgui was written.

OK, so this is version 0.01. I've been able to retrieve a list of things to monitor (that's the long list of OIDs above). Clearly that needs prettifying a bit - a tree view would be a nice next step. And I can retrieve values and produce pretty charts. That's incoming bytes on my main network interface.
It's a simple proof of concept - but it proves that something can be done pretty easily, and that it works.
This is easy, right. So a little while later snmpgui was written.
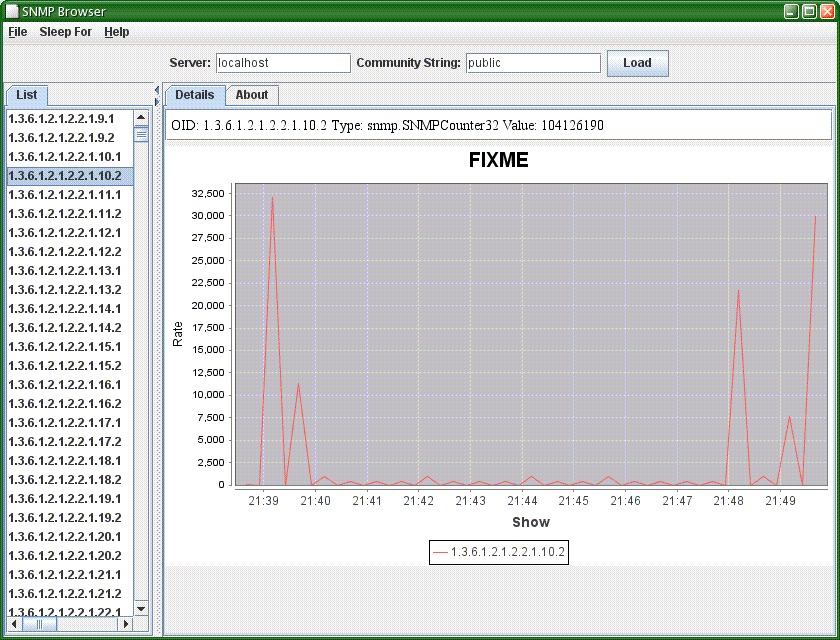
OK, so this is version 0.01. I've been able to retrieve a list of things to monitor (that's the long list of OIDs above). Clearly that needs prettifying a bit - a tree view would be a nice next step. And I can retrieve values and produce pretty charts. That's incoming bytes on my main network interface.
It's a simple proof of concept - but it proves that something can be done pretty easily, and that it works.
SolView 0.46
I've uploaded a new version of SolView. This broadly corresponds to the version I talked about at LOSUG, with one new feature.
I've improved the Jumpstart Profile Builder by adding the ability to import an existing jumpstart profile. The idea is to use this as an initial customization of the set of installed packages that you can then modify further.
In practice, this didn't work out anything like as well as I wanted it to. One of the constraints I place upon the construction of a profile is that the package selection be self consistent: package dependencies must be satisfied. (Indeed, it was the desire to be able to construct such profiles that led to writing the profile builder in the first place.) However, most existing profiles have customizations that lead to unsatisfied package dependencies. Often, fixing up such profiles as they are imported ends up simply undoing all your customizations.
The current implementation is just a first pass, so I could improve it. For example, if it encounters a dependency error on import, it could ask you whether you want to keep the customization (and add or remove other packages as necessary) or ignore the customization. The problem is that this gets you into a horrible rats nest very quickly.
In practice, I find it easier to build a new profile based on an existing one by eye - looking at what I'm trying to add or remove and replicating that in the jumpstart profile builder.
So I'm tempted not to invest too much time on this feature. However, one thing I should be able to do relatively easily is to take the import code and use it to build a profile based on a straight list of packages. For example, this could be used to generate a jumpstart profile that would reproduce an existing installed system.
I've improved the Jumpstart Profile Builder by adding the ability to import an existing jumpstart profile. The idea is to use this as an initial customization of the set of installed packages that you can then modify further.
In practice, this didn't work out anything like as well as I wanted it to. One of the constraints I place upon the construction of a profile is that the package selection be self consistent: package dependencies must be satisfied. (Indeed, it was the desire to be able to construct such profiles that led to writing the profile builder in the first place.) However, most existing profiles have customizations that lead to unsatisfied package dependencies. Often, fixing up such profiles as they are imported ends up simply undoing all your customizations.
The current implementation is just a first pass, so I could improve it. For example, if it encounters a dependency error on import, it could ask you whether you want to keep the customization (and add or remove other packages as necessary) or ignore the customization. The problem is that this gets you into a horrible rats nest very quickly.
In practice, I find it easier to build a new profile based on an existing one by eye - looking at what I'm trying to add or remove and replicating that in the jumpstart profile builder.
So I'm tempted not to invest too much time on this feature. However, one thing I should be able to do relatively easily is to take the import code and use it to build a profile based on a straight list of packages. For example, this could be used to generate a jumpstart profile that would reproduce an existing installed system.
Subscribe to:
Posts (Atom)